Analysis of Malicious Document 4

In the last part of this article series, we have seen the structure of PDF document and all the essential keywords which can be used by analysts to carry investigations and are also used by various tools to depict the nature of the document being analyzed.
Below is a refresher of important keyword concerning PDF document analysis.

Become a certified reverse engineer!
- /AA: This defines the Automatic Actions that is embedded in the document when the user opens the document. It should be noted that events an also declared inside this like cursor movement to trigger a particular action.
- /AcroForm: This shows whether Adobe forms are used in PDF documents or not.
- /ObjStm: This is used to define object stream which can hide specific other objects. We will see this in the later part of the series.
- /JS: Embedded JavaScript within the document.
- /GoTo*: Redirected to the specified destination in the PDF file.
- /URI: Resource accessed as pointed by URL
- /SubmitForm and /GoToR: This indicates the data send to the URL.
- /Launch: This launches a program.
Let's start the analysis of PDF documents.
Using pdfid, an analyst can perform initial, quick analysis of PDF documents. As stated above this tool checks for the important keywords in the document and depict their actions. This utility is a part of Didier Steven's PDF tools. Let's see this utility in action
Below is the pdfid utility in action on a malicious PDF file samplepdf.pdf. Run the pdfid utility on document like below

Pdfid found out the references to keywords inside the pdf file. Let's try to understand these references a bit better.
This PDF file is 1 page long(/Page) and has at least one instance of JavaScript(/Javascript) and Automatic Action(/AA) embedded into it. This pdf document also contains the Adobe forms(/AcroForm).
We can also get the metadata of the document by using the –extra switch with the pdf id tool like below
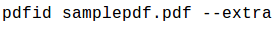
We can get necessary metadata from the document like creation date, modified date, entropy value for different sections/streams, however, the analyst must note that these fields can be easily changed by the malicious author and should not be trusted by the analysts to form the basis of any investigation.
Now we have found indicators of this file being malicious; we need to know the content of the file. We cannot do it with pdfid, but there is another utility available known as pdf-parser which can help us to point to the object and extract the content out of PDF file.
Let's see pdf-parser in action:
Pdfparser has a --search option which can help us to search for the objects. We have seen earlier that pdfid found out an embedded JavaScript. Let's try to locate that object with pdfparser

Moreover, it will give us the following output
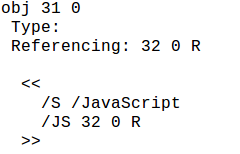
This can be deciphered as the utility found the Object number 31 containing /Javascript string. Inside this, we can see a reference to object 32(if you remember we have seen in the previous article about this. Keyword 'R' denotes a reference to object and in this case, object 31 refers to Object 32 means Object 31 is going to execute the JavaScript stored in Object 32.)
Now we need to find the object 32, and for that, we have the –object switch to use with pdf-parser.py. We can use it like below
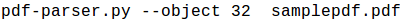
Moreover, we will see output like below
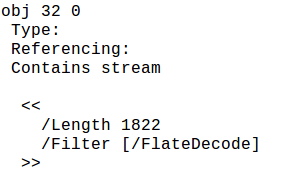
So, this object (Object 32) contains a stream of length 1822 bytes, and it is compressed& encoded using FlateDecode.
Now to decompress the stream, pdf-parser.py has a –filter switch and also a –raw switch to keep the output without escaping special characters.
This JS is looking for the version of PDF viewer (Adobe Acrobat in this case)
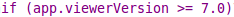
From the above code, we can see that the variable 'sc' seems to hold the shellcode. JS checks for PDF viewer version, and if it is lower than 6.0, then it tries to exploit a buffer vulnerability in the Collab.CollecEmailInfo by passing a crafted variable to it (plin in this case) as the value of msg parameter.
After that, it invokes the start() function with app.setTimeout which is used to execute the function after a specified amount of time (10 milliseconds in this case).

Now since we know that shellcode is inside the 'sc' variable and we need to analyze how it will work, we need to make an exe out of the shellcode. For that first, we need to copy the contents of sc variable and remove all the garbage from it like below.
And then we need to convert the Unicode to hex characters. There can be a simple customized script to build for that like to replace %u with x.
I will be using unicode2hex-escaped script that comes shipped with Remnux to make the conversion
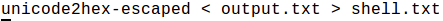 t
t
Now since we have the shellcode in hex format, now we can use a utility such as shellcode2exe.py to convert the txt file into an exe file. Use shellcode2exe utility like below
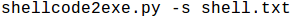
And we will get the output like below

Since the exe is available now, now normal analysis using debugger and disassembler can continue.
Become a certified reverse engineer!
In this article we have seen how we can parse the structure of a PDF file identifying essential keywords, enumerating objects, identifying vulnerabilities, extracting shellcode and converting it into an exe for further analysis. In the next and last part of this article series, we will take a look at other tools to perform the analysis.


- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this series
- Analysis of Malicious Document 4
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
