OllyDbg

Introduction
OllyDbg is a 32-bit debugging tool used to analyze binary code. Its popularity is tied to the fact that people can do so despite not having access to the source code. OllyDbg can be used to evaluate and debug malware. OllyDbg is a popular debugger due to its ease of use and being freeware.

Malware analysis
OllyDbg is useful in analyzing malware. If you plan to analyze malware on your own, you want to ensure you have your environment setup to protect yourself and your assets. This should be done in a closed environment within a virtual machine. Using a virtual machine is not enough. Do some research on best ways to isolate your environment. Avoid using bridged mode, as it leaves your network exposed.
OllyDbg is meant to run on a Windows platform. If you are creating a virtual environment using Kali Linux instead of Windows, you will need to use Wine to run OllyDbg. This is important to note, as many researchers prefer using Kali Linux for analysis.
It’s important to note that if using a dissembler, it is expected the user have knowledge of the assembly language. It will help tremendously in the evaluation of the code.
Debugging
Evaluating malware normally involves using multiple tools. OllyDbg is just a debugger, so before you begin, you may want to determine all the information you want to retrieve from the code. Other tools like Wireshark, PE editor, IDA Pro and more may come in handy.
If you perform static analysis of malware code, the code is not actually executed. A dynamic analysis is an observation of the live code and gives a deeper picture of the functionality of the malware.
In order to perform a true dynamic analysis, you may want to allow your host to get infected while running a network analyzer like Wireshark. You would evaluate the results in Wireshark to see what type of network calls and other activity takes place. This gives you a network behavioral analysis.
The evaluation process
Once you have the malware you want to evaluate, you can directly upload the executable into OllyDbg. We are going to take a look at what the WannaCry worm.
WannaCry is ransomware that appeared in 2017 but is still considered one of the biggest malware threats out there. Due to its continued havoc, it has been highly researched and evaluated.
If you choose to launch WannaCry in a closed environment, you will see the following message:
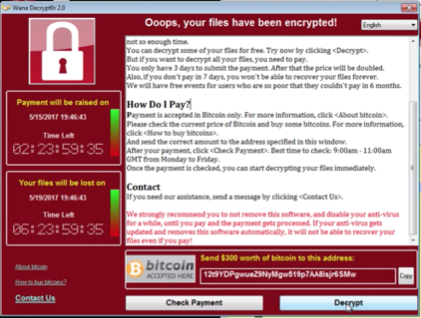
With the below message cryptically lingering in the background:
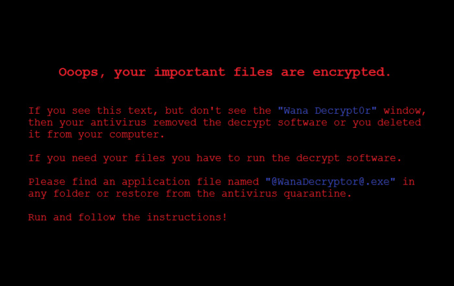
WannaCry was designed to infect Windows systems.
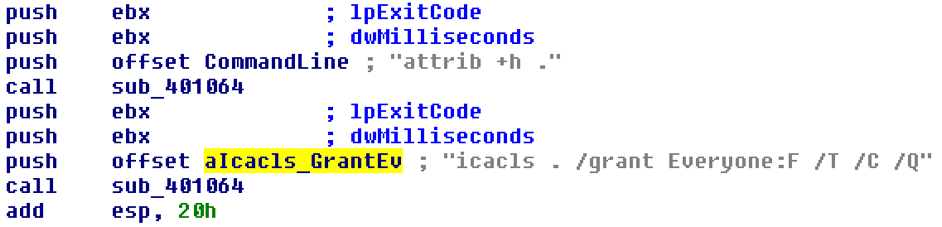
In an initial evaluation of the code we find that once executed, it runs the attrib +h command.
The attrib command is used to change the attributes of files. This particular command changes all files to hidden. It then executes the icacls ./grant Everyone:F /T /C /Q command. The embedded encryptor launches to encrypt the files and to display the above messages, which starts the timer.
To do further analysis, you will need to obtain the wannacry_dropper.exe and upload it into OllyDbg. Once uploaded, here is a snippet of the initial view you will see:
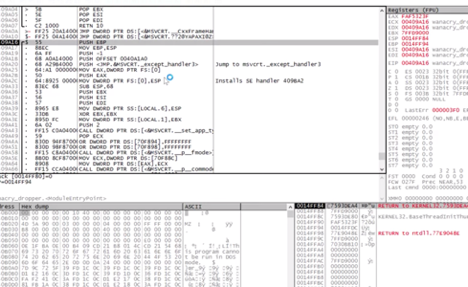
WannaCry makes changes to the Windows registry and loads a password-protected file named “XIA.” Security researchers have discovered the password to be “WNcry@2oI7”.
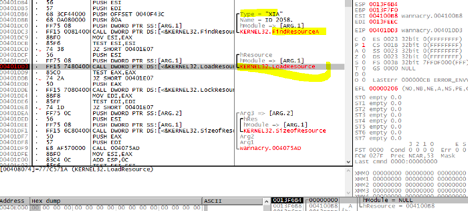
The XIA file contains the other binaries used to encrypt the files on the now-infected system.
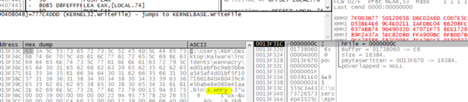
This includes the s.wnry cry file as shown above.
Malware researchers often want to identify the strings associated with the malicious code. Identifying the strings can help to understand the functionality of the code. While evaluating the executed malware and network activity in Wireshark, you may have identified a URL that the code tries to access after execution. Evaluating the strings could also confirm URLs in use by the code.
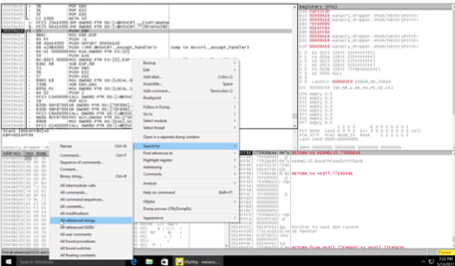
After uploading the code, you can right-click and in the “Search for” option select “All reference Strings”. This will open a new window with all of the found string references in the code.
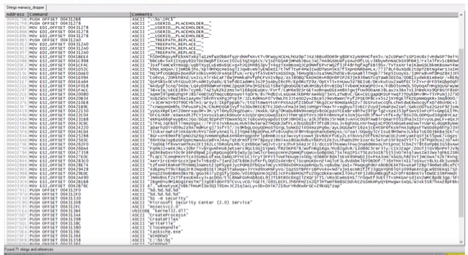
In evaluating the strings, we can see various API calls, placeholders, create commands and so on, but as we scroll through, we also find a hardcoded URL reference. See below:
![]()
If you press F9 while at the URL reference line, you will be able to create a breakpoint for further evaluation. As we continue to look deeper into that function, we can see an internet call:

This gives the malware details on opening that particular URL and how to function if it cannot be reached or does not return expected results.
As you continue to examine the calls, you can identify another encrypt function:
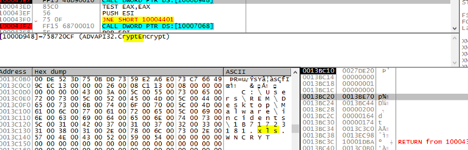
This takes the files identified and exchanges the original extension, e.g., .xls, and replaces it with wncry.
You can continue to dig further into the call functions to understand how each interacts with the internet. You can also return to the main window and perform other searches. You can search for any of the following, as shown in the image below:
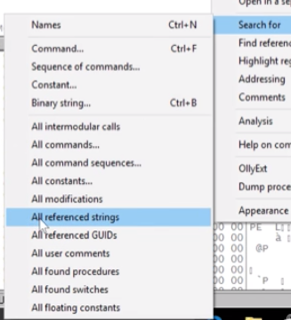
- All intermodular calls
- For clarification, this is a list of functions called from the main module. The rest of the list if self-explanatory
- All commands
- All command sequences
- All constants
- All modifications
- All referenced strings
- All references GUIDs
- All user comments
- All found procedures
- All found switches
- All floating constants
Packed malware
OllyDbg is also useful in disassembling and analyzing packed malware. There are articles within the Infosec website that detail how to use OllyDbg for this purpose, so we won’t reiterate that here.
Conclusion
OllyDbg is a power disassembler that can prove useful in the analysis of malware. It can be used alone to perform a static analysis of the executable or in conjunction with other tools to perform a dynamic analysis of the executed dropper. Malware analysis can be fun but ensure you only perform analysis in a secure environment to avoid affecting yourself or others.
Sources
- Why you need you a Malware Analysis Lab and How to build it, Medium
- WannaCry 2.0 - Three ways to find the Kill Switch, Colin Hardy (YouTube)
- WannaCry: A cheat sheet for professionals, TechRepublic
- WANACRYPT0R RANSOMWORM, BAE Systems Threat Research Blog
- Malware Analysis of WanaCry Ransomware, Abdurrahman Akkas, Christos Nestoras Chachamis, Livio Fetahu
- WannaCry Malware Profile, FireEye
- WCry Ransomware Analysis, Secureworks
- WannaCry 2.0 Ransomware, Colin Hardy (YouTube)
- What is WannaCry ransomware, how does it infect, and who was responsible?, CSO
- Quick start - version 1.10, OllyDbg
- A Technical Analysis of WannaCry Ransomware, LogRhythm
- WannaCry Ransomware Analysis and Decryption Methodology, Medium
- WannaCry: We Want to Cry, Trustwave

- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this series
- OllyDbg
- How AsyncRAT is escaping security defenses
- Chrome extensions used to steal users' secrets
- Luna ransomware encrypts Windows, Linux and ESXi systems
- Bahamut Android malware and its new features
- LockBit 3.0 ransomware analysis
- AstraLocker releases the ransomware decryptors
- Analysis of Nokoyawa ransomware
- Goodwill ransomware group is propagating unusual demands to get the decryption key
- Dangerous IoT EnemyBot botnet is now attacking other targets
- Fileless malware uses event logger to hide malware
- Nerbian RAT Using COVID-19 templates
- Popular evasion techniques in the malware landscape
- Sunnyday ransomware analysis
- 9 online tools for malware analysis
- Blackguard malware analysis
- Behind Conti: Leaks reveal inner workings of ransomware group
- ZLoader: What it is, how it works and how to prevent it | Malware spotlight [2022 update]
- WhisperGate: A destructive malware to destroy Ukraine computer systems
- Electron Bot Malware is disseminated via Microsoft's Official Store and is capable of controlling social media apps
- SockDetour: the backdoor impacting U.S. defense contractors
- HermeticWiper malware used against Ukraine
- MyloBot 2022: A botnet that only sends extortion emails
- Mars Stealer malware analysis
- How to remove ransomware: Best free decryption tools and resources
- Purple Fox rootkit and how it has been disseminated in the wild
- Deadbolt ransomware: The real weapon against IoT devices
- Log4j - the remote code execution vulnerability that stopped the world
- Rook ransomware analysis
- Modus operandi of BlackByte ransomware
- Emotet malware returns
- Mekotio banker trojan returns with new TTP
- Android malware BrazKing returns
- Malware instrumentation with Frida
- Malware analysis arsenal: Top 15 tools
- Redline stealer malware: Full analysis
- A full analysis of the BlackMatter ransomware
- A full analysis of Horus Eyes RAT
- REvil ransomware: Lessons learned from a major supply chain attack
- Pingback malware: How it works and how to prevent it
- Android malware worm auto-spreads via WhatsApp messages
- Malware analysis: Ragnarok ransomware
- Taidoor malware: what it is, how it works and how to prevent it | malware spotlight
- SUNBURST backdoor malware: What it is, how it works, and how to prevent it | Malware spotlight
- ZHtrap botnet: How it works and how to prevent it
- DearCry ransomware: How it works and how to prevent it
- How criminals are using Windows Background Intelligent Transfer Service
- How the Javali trojan weaponizes Avira antivirus
- HelloKitty: The ransomware affecting CD Projekt Red and Cyberpunk 2077
- DreamBus Botnet: An analysis
- Kobalos malware: A complex Linux threat
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!

Malware analysis
Learn more about the popular and dangerous AsyncRAT malware.


Malware analysis
Learn how Chrome extensions are being used for nefarious purposes.

Malware analysis
Criminals use the Rust and Goland programming languages to develop new threats.

Malware analysis
Learn all about the Bahamut malware that is once again infecting devices.