Writing Your Own Parser


Writing Data Format Parsers

FREE role-guided training plans
Abstract
File format parsing and converting for further processing is a fundamental activity in many computer software-related tasks. Taking cues from the gaming community, wherein graphics files are converted from one format to another by writing custom parsers, we will proceed with the steps of writing parsers for the DEX android file for the Dalvik VM.
What Is a File Format?
A file format is, in its simplest abstraction, a data structure. A data structure is a specific arrangement, or format, of data. In this context, the organization of data elements in memory or filesystem would entail a linear sequence of bytes.
It is not necessary for every file format to have something called the header or metadata (like a table of contents for the file, it describes the data, without necessarily being the data itself) that describes the various 1) locations and 2) lengths of the individual data elements contained in the file structure. Locations specify from where to start looking and lengths specify the number of bytes covered. Basically, when you are dealing with such a file format, you need to look at the specifications/documentation provided by the vendor or author of the file format or reverse engineer the parsing code from the software that uses it. In our case, DEX format is very well described indeed. In cases where you don't get a detailed specification from the authors of the file formats, reverse engineering the software that makes use of that format would be needed. A quick online check for resources for file format specifications take us to sites like Wotsit.org, which serves as a repository for various software and hardware formats. There are some caveats though: Quite a few of the links don't work, the formats are not all complete submissions, and the list of formats is selective and not a total list of all formats available. Many closed source formats are just not there.
Brief Overviews
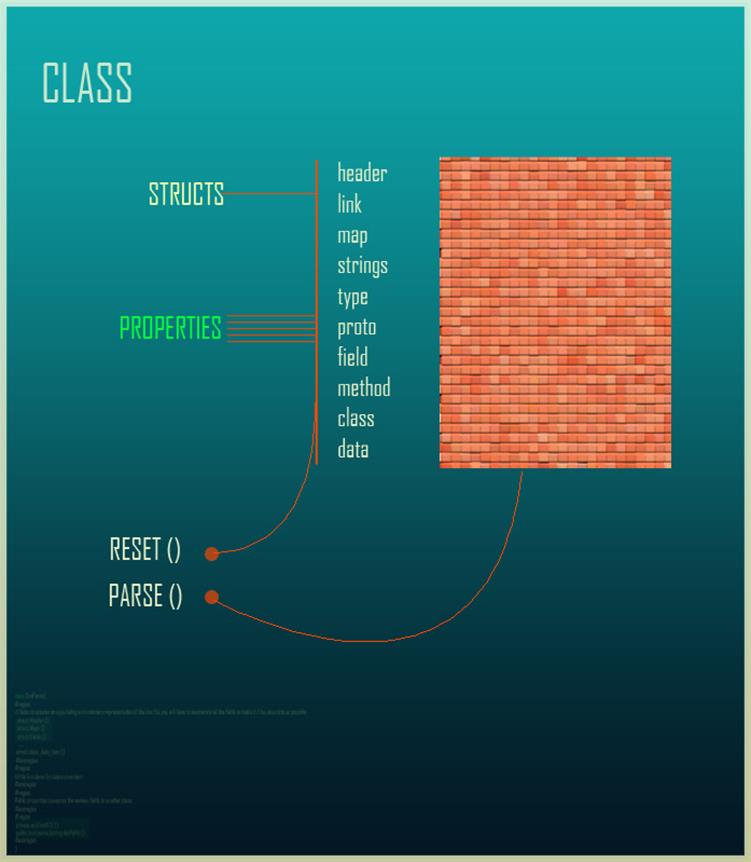
The DEX file format is a little bit involved. It consists of a header that clearly demarcates where the file sections start from. Each file section contains a certain type, for instance, a MAP LIST, METHOD LIST, CLASS LIST, STRINGS LIST, and the like. The header specifies the location and the size of each. It also makes use of the ULEB128 data type for parsing certain sections data types. Further, each of the sections must to be parsed deeply, as in levels and sub-references within each section, and, finally, the extracted information must be cross-referenced to fully extract all the structures contained within. Our goal is to extract the instruction bytes array in each method that contains the opcodes so that these arrays can be sent to the Dalvik disassembler later on.
Most file formats have something that gives away its format type in the first few bytes—its "tell." These unique sequences of bytes are "magic numbers." It would therefore be simple enough to build a file type identifier that simply reads the first few bytes and then detects the patterns. PE files have a "MZ" 0x4D5A pattern at the very beginning of the file. DEX files have a "DEX" string at the outset as well. While not as foolproof as parsing the entire file for a detailed description, this method is certainly a traditional method for preliminary format identification.
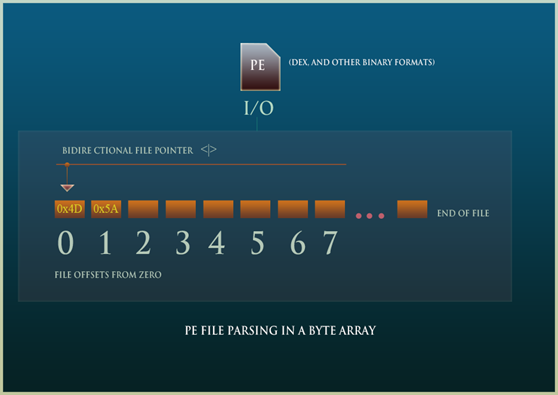
We will extract the entire file as a byte array for ease of traversal and memory performance. The entire file is one long series of bit patterns. Grouping that into a sequence of bytes immediately makes the indexing and parsing a more linear activity.
The general approach is depicted in the diagram below:
Data Sheets
This word comes from hardware specifications or data sheets for chipsets and microprocessors. In terms of file formats like PE and DEX, the documentation is the data sheet. We need the specifications of each format to get a better understanding of how the data is organized before we start coding the parsing class. Let's start with the DEX file specification and see if we can make any sense of it. The Android Open Source Project site gives a good listing. A few excerpts are given below.
A sample malware android apk file has the folder structure shown below when opened in Windows:

Every component can be parsed in this directory structure—the zip (apk!) file, the binary XML, AndroidManifest.XML (apk config file), the classes.dex file, each of the files in the folders could be parsed recursively and checked for file extension validity and entropy values to look for anomalies. However for now we are focused only on classes.dex. Every apk has only one of them containing all the code and classes required for the execution of the apk.
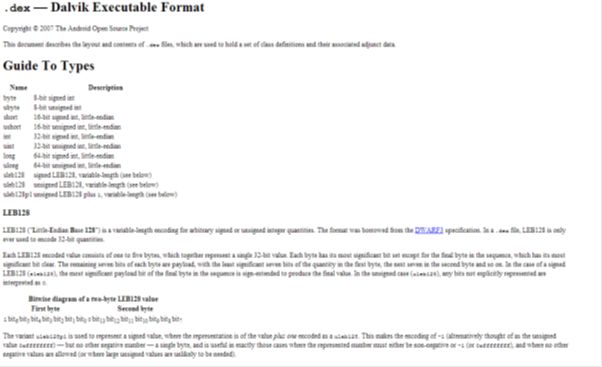
Take a good look at the list of data types supported in the dex file. Their bit sizes immediately give their memory space requirements. Among them you have unsigned and signed types that run from a byte, word, dword, qword, to the LEB signed/unsigned types. These types are variable length. The bio of this data type is interesting and you should get the requisite information for the custom type conversion code. We will implement the same logic in our parser.

This part of the document gives us an overview of the entire file layout. Read the descriptions and make notes of what types are contained in which sections and how they are arranged and organized.

This part of the document details the specific data types for reaching out to the different file sections. Notice the regular pattern of SIZE followed by OFFSET. All of these values are expressed by a positive integer data type. We have a SHA signature that is 20 bytes long. The magic sequence at the outset is exactly 8 bytes long.

To round off, we have eight areas to parse, excluding the initial header. Strings are very important in binary executables, and we will extract them from the dex file as well. Let us focus on the string_ids segment. The size and offset are specified.

The excerpt above is for the strings_ids sections of the dex file. Each string data item appears in the data section. Note that each string item is a ULEB type. The offset specified in the string_data_offset uint type provides the offset from the start of the file to the string data located in the data section further down the file.

Next we try to locate where the executive opcodes are. You will find that they are in the code_item structure that is referenced from the method_item type. The insns field within the code_item structure contains an array of 2-byte sized elements (4-byte alignment is also done with larger opcodes, thus overriding the default spec) of rank specified in the preceding field, "insns_size." Each method can be either virtual or direct, as the dex file is itself converted from the .class files of a java application. The class_data_item structure references these method lists. The class_data_item is referenced from the class_def_item structure in the class_defs section.
Therefore, you have to start parsing from one section and keep digging into other sub-referenced sections to finally extract the opcode array.

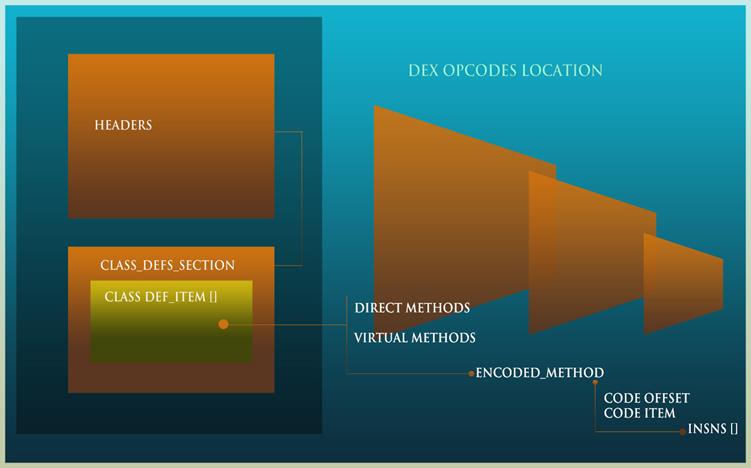
Now that we have read the specifications, we have a good understanding of the overall layout of the dex file, its headers, data types, and the total number of items. We have to deal with a custom data type LEB to extract strings from the data section. We also have to parse the headers to locate each of the referenced items to get to the instructions array.
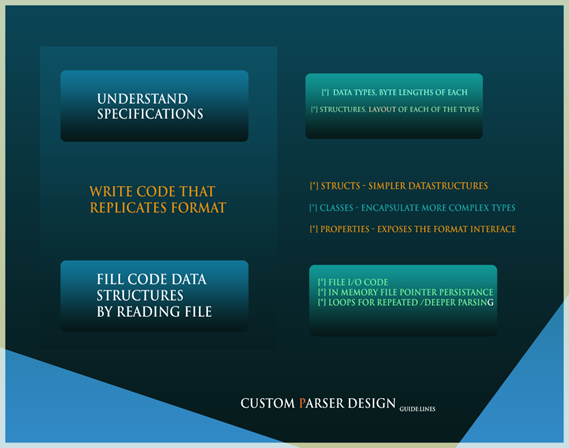
WRITING THE PARSER
The parser is in C#. This means complete access to OOP & OOD.
- First we get the ULEB128 data type done in code because important members later on, including the code item structures, use this type.
- Thereafter we proceed with the I/O code to manage the in-memory representation of the dex binary file. To enable this, we code a filepointer persistence function that keeps track of the current byte position in the parser.
- Finally, the actual parsing begins from the in-memory byte array and the class members for the dex file structures are filled in by traversing the byte array. Once it is filled in, we dig into the instruction array and store the opcodes for retrieval for the disassembler class. After this we are done!
ULEB DATA TYPE CONVERSION
[c]
#region Utility functions
private List<byte> ULEB128(byte[] fIm, int startIdx)
{
List<byte> _ulb = new List<byte>();
for (int i = startIdx; i < fIm.Length; i++)
{
int[] rep = bitConv(fIm[i]);
if (rep[0] != 0)
{
_ulb.Add(fIm[i]);
}
else { _ulb.Add(fIm[i]); break; }
}
// currentOffset += _ulb.Count;
return _ulb;
}
[*] Saving the file in memory as a byte [], its important to keep the current file pointer updated. Lend is a function for converting to LITTLE ENDIAN.
[c]
private string byteWalker(List<byte []> fd, int startOf, int length) {
StringBuilder sb =new StringBuilder();
for (int i = startOf; i < startOf+length; i++) {
sb.Append(fd[0][i].ToString("X2"));
}
currentOffset = startOf + length;
return lend(sb.ToString());
public string lend(string b) {
StringBuilder sb=new StringBuilder();
for (int i = b.Length; i>=0; i-=2){
if (i-2!=-2){
sb.Append(b.Substring(i-2,2));
}else {break;}
}
return sb.ToString();
private int[] bitConv(byte f)
{
int[] bits = new int[] { 0, 0, 0, 0, 0, 0, 0, 0 };
int tp = f;
for (int j = 7; j >= 0; j--)
{
if (tp > 0)
{
if (tp % 2 != 0)
{
bits[j] = 1;
tp = tp / 2;
}
else { tp = tp / 2; }
}
else { break; }
}
return bits;
private string Payload(List<byte> y)
{
List<int> total = new List<int>();
for (int i = y.Count - 1; i >= 0; i--)
{ //process each byte
int[] temp = bitConv(y[i]); //get the bit pattern
for (int j = 1; j <= 7; j++)
{
total.Add(temp[j]); //accumulate the 7 bits
}
}
if (total.Count % 8 != 0)
{
total.Reverse(0, total.Count);
while (total.Count % 8 != 0)
{
total.Add(0);
}
total.Reverse(0, total.Count);
}
else
{
//total.Reverse(0, total.Count); //swapping Little Endian}
}
return BinConv(total);
}
private string BinConv(List<int> f)
{
int Nu = 0; int count = 0;
for (int i = f.Count - 1; i > 0; i--)
{
Nu += f[i] << count;
count++;
}
return Nu.ToString("X2");
#endregion
[/c]
The Overall Class AND Members
The parsing function:
This function returns a bool value of true or false. If the parsing fails for any reason, it won't parse any further. The catch exception handler is more involved and reports what part has failed and clears all the data structures. Here it's not shown for brevity.
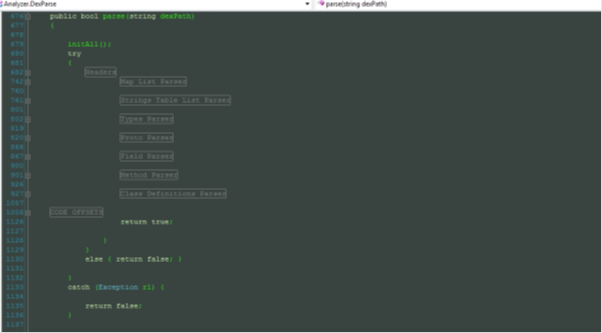
[c]
public bool parse(string dexPath)
initAll();
try
{
#region Headers
_fileImage.Add(File.ReadAllBytes(dexPath));
string Magic = _fileImage[0][0].ToString("X2") + _fileImage[0][1].ToString("X2")
if (Magic == "6465780A" && _fileImage[0][7].ToString("X2") == "00")
{
//save magic value and continue parsing
dh.VERSIONS = ((char)(_fileImage[0][4])).ToString() + ((char)(_fileImage[0][5])).ToString()
+ ((char)(_fileImage[0][6])).ToString();
dh.CHECKSUM = _fileImage[0][8].ToString("X2") + _fileImage[0][9].ToString("X2")
dh.SIGNATURE = byteWalker(_fileImage, 12, 20);
dh.FILESIZE = byteWalker(_fileImage, currentOffset, 4);
dh.HEADERSIZE = byteWalker(_fileImage, currentOffset, 4);
if (EndianTag != "12345678")
{
return false;
//("Only Endian-encoded files are supported");
}
else
{
dh.ENDIANTAG = EndianTag;
dh.LINKOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.MAPOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.STRINGSSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.STRINGSOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.TYPEREFERENCESSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.TYPEREFERENCESOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.PROTOTYPESSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.PROTOTYPESOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.FIELDREFERENCESSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.FIELDREFERENCESOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.METHODREFERENCESSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.METHODREFERENCESOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.CLASSDEFINITIONSSIZE = byteWalker(_fileImage, currentOffset, 4);
dh.CLASSDEFINITIONSOFFSET = byteWalker(_fileImage, currentOffset, 4);
dh.DATASIZE = byteWalker(_fileImage, currentOffset, 4);
dh.DATAOFFSET = byteWalker(_fileImage, currentOffset, 4);
#endregion //set
#region Map List Parser
if (Convert.ToInt32(dh.MAPOFFSET,16)!=0){
//list count
int mapsize = Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4),16);
for (int i = 0; i < mapsize; i++)
{
Maps mx = new Maps();
mx.TCODES =(TypeCodes)Convert.ToUInt16(byteWalker(_fileImage, currentOffset, 2),16);
currentOffset += 2;
mx.TSIZE = byteWalker(_fileImage, currentOffset, 4);
mx.TOFF = byteWalker(_fileImage, currentOffset, 4);
_mapMan.Add(mx);
//TODO
}
}
#region Strings Table List Parser
uint StringSize= Convert.ToUInt32(dh.STRINGSSIZE,16); //string item count
if (StringSize != 0)
{
currentOffset = Convert.ToInt32(dh.STRINGSOFFSET, 16);
int StringStart = currentOffset;
//MemoryStream ms = new MemoryStream(_fileImage[0]);
//BinaryReader sb = new BinaryReader(ms);
int StringsDataOffset = Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4), 16);//1st string entry
StringBuilder t = new StringBuilder(); string sOff = "";
for (int i = StringsDataOffset + 1; i < _fileImage[0].Length; i++) //
{
if (itemCounter >= StringSize) { break; }
else
{
if (_fileImage[0][i].ToString("X2") != "00")
{
if (sOff == "")
{
sOff = i.ToString("X2");
}
}
else
{
_strin.Add(sOff+","+t.ToString()); t.Remove(0, t.Length); i += 1;
itemCounter += 1; sOff = "";
}
}
}
#endregion //set
#region Types Parser
uint TypeCount=Convert.ToUInt32(dh.TYPEREFERENCESSIZE, 16);
if (TypeCount != 0)
{
for (int i = 0; i < TypeCount; i++)
{
int off = currentOffset;
Int32 idx = Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4), 16);
}
}
#region Proto Parser
uint ProtoCount = Convert.ToUInt32(dh.PROTOTYPESSIZE, 16);
if (ProtoCount != 0)
{
for (int i = 0; i < ProtoCount; i++)
{
Protos p = new Protos();
p.ShortyIdx=_strin[Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4),16)];
p.RetIdx =((TypeDescriptors)(_types[Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4),16)].Split(',')[3].Substring(0,1).ToCharArray()[0])).ToString();
p.ParOff = byteWalker(_fileImage, currentOffset, 4);
//delve into the type_list
if (Convert.ToInt32(p.ParOff, 16) != 0)
{
uint listCount = Convert.ToUInt32(byteWalker(_fileImage, Convert.ToInt32(p.ParOff, 16), 4));
for (int j = 0; j < listCount; j++)
{
TypeItem tt = new TypeItem();
//currentOffset = Convert.ToInt32(p.ParOff, 16) + 4;
tt.IDX = byteWalker(_fileImage, currentOffset, 2);
if (Convert.ToInt16(tt.IDX, 16) < _types.Count)
{
tt.ItemString = _types[Convert.ToInt16(tt.IDX, 16)];
}
else { tt.ItemString = ""; }
_tList.Add(tt);
}
p.TYPERLIST = _tList;
//delving ends here
currentOffset = saveCurrent;
//Enumerate the parameter list
p.ProtoString = p.ShortyIdx.Split(',')[1] + " " + p.RetIdx;
}
}
#region Field Parser
uint FieldCount = Convert.ToUInt32(dh.FIELDREFERENCESSIZE, 16);
if (FieldCount != 0)
{
for (int i = 0; i < FieldCount; i++)
{
Fields f = new Fields();
int off = currentOffset;
f.ClassIdx=byteWalker(_fileImage, currentOffset, 2);
f.TypeIdx = byteWalker(_fileImage, currentOffset, 2);
string cdx=_types[Convert.ToUInt16(f.ClassIdx,16)];
string tdx = _types[Convert.ToUInt16(f.TypeIdx, 16)];
string ndx = String.Empty;
try
{
ndx = _strin[Convert.ToInt32(f.NameIdx, 16)];
}catch(ArgumentOutOfRangeException jkj){}
try
{
TypeDescriptors fg = (TypeDescriptors)tdx.Split(',')[3].Substring(0, 1).ToCharArray()[0];
f.FieldString = fg.ToString() + " " + cdx.Split(',')[3] + "." + tdx.Split(',')[3] + " "; //+ ndx.Split(',')[1] add later after bugchk
_fields.Add(f);
}
}
}
#region Method Parser
uint MethodCount = Convert.ToUInt32(dh.METHODREFERENCESSIZE, 16);
if (MethodCount != 0)
{
for (int i = 0; i < MethodCount; i++)
{
Methods f = new Methods();
int off = currentOffset;
f.ClassIdx = byteWalker(_fileImage, currentOffset, 2);
f.ProtoIdx = byteWalker(_fileImage, currentOffset, 2);
f.NameIdx = byteWalker(_fileImage, currentOffset, 4);
//TODO proto_ids list ref
string cdx = _types[Convert.ToUInt16(f.ClassIdx, 16)];
string pdx = _prot[Convert.ToUInt16(f.ProtoIdx, 16)].ProtoString;
//string ndx = _strin[Convert.ToInt32(f.NameIdx, 16)];
//TypeDescriptors fg = (TypeDescriptors)tdx.Split(',')[3].Substring(0, 1).ToCharArray()[0];
f.FieldString = cdx.Split(',')[3] + "." + pdx + " "; // + ndx.Split(',')[1] //add after bugchk
}
}
#region Class Definitions Parser
uint classCount=Convert.ToUInt32(dh.CLASSDEFINITIONSSIZE,16);
if (classCount != 0) {
currentOffset = Convert.ToInt32(dh.CLASSDEFINITIONSOFFSET, 16);
for (int i = 0; i < classCount; i++) {
string d1 = byteWalker(_fileImage,currentOffset,4);
string d2 = byteWalker(_fileImage, currentOffset, 4);
string d3 = byteWalker(_fileImage, currentOffset, 4);
string d4 = byteWalker(_fileImage, currentOffset, 4);
string d5 = byteWalker(_fileImage, currentOffset, 4);
string d6 = byteWalker(_fileImage, currentOffset, 4);
//currentOffset+= 24;
cd.ClassData = Convert.ToUInt32(byteWalker(_fileImage,currentOffset,4),16);
_classDef.Add(cd);
string d7 = byteWalker(_fileImage, currentOffset, 4);
}
//iterate each class def item , here only the Class Data Item is ref
foreach (class_def_item r in _classDef ){
if (r.ClassData != 0) {
int itemCount=0;int delta=0;
class_data_item ci = new class_data_item();
currentOffset = Convert.ToInt32(r.ClassData);
while (itemCount < 4) //first 4 fields
{
List<List<byte>> g=new List<List<byte>>();
g.Add(ULEB128(_fileImage[0], currentOffset));
delta = g[0].Count;
switch (itemCount){
case 0 : ci.STAT_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 1: ci.INST_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 2:ci.DIR_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 3: ci.VIR_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
default :break;
itemCount++;
}
ci.STAT_F = new List<encoded_field>();
for (uint i=0 ;i<Convert.ToUInt32(ci.STAT_F_S,16);i++){
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
currentOffset+=g1[0].Count;g1.Clear();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.ACC_FLG=Payload(g1[0]);
ci.STAT_F.Add(ef); //store the fields list for this class_data_item
}
ci.INST_F = new List<encoded_field>();
for (uint i=0 ;i<Convert.ToUInt32(ci.INST_F_S,16);i++){
encoded_field ef=new encoded_field();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.FIELD_DFF=Payload(g1[0]);
currentOffset+=g1[0].Count;g1.Clear();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.ACC_FLG=Payload(g1[0]);
ci.INST_F.Add(ef);//store the instance lists
}
ci.DIR_F = new List<encoded_method>();
for (uint i=0 ;i<Convert.ToUInt32(ci.DIR_F_S,16);i++){
encoded_method em=new encoded_method();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.MET_IDX=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.ACCESS_FLAGS=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.CODE_OFF=Payload(g1[0]);
ci.DIR_F.Add(em);
}
ci.VIR_F = new List<encoded_method>();
for (uint i=0 ;i<Convert.ToUInt32(ci.VIR_F_S,16);i++){
encoded_method em=new encoded_method();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.MET_IDX=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.ACCESS_FLAGS=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.CODE_OFF=Payload(g1[0]);
ci.VIR_F.Add(em);
}
_classDataItem.Add(ci); //store the class_data_items
}
#endregion
#region CODE OFFSETS
foreach (class_data_item d in _classDataItem) {
foreach (encoded_method em in d.DIR_F) {
currentOffset= Convert.ToInt32(em.CODE_OFF, 16);
code_item co = new code_item();
co.REG_Sz = byteWalker(_fileImage,currentOffset,2);
co.INSWORD_Sz = byteWalker(_fileImage, currentOffset, 2);
co.OUTS_Sz = byteWalker(_fileImage, currentOffset, 2);
co.TIRES_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INS_COUNT = byteWalker(_fileImage, currentOffset, 4);
List<byte> flare = new List<byte>();
for (int i = 0; i < Convert.ToInt32(co.INS_COUNT,16); i++)
flare.Add(Convert.ToByte(byteWalker(_fileImage,currentOffset,1),16));
}
co.INSTRUCTIONS=new List<List<byte>>();
co.INSTRUCTIONS.Add(flare);
//leave the rest for later
_codeRep.Add(co);
}
foreach (class_data_item d in _classDataItem)
{
foreach (encoded_method em in d.VIR_F)
{
currentOffset = Convert.ToInt32(em.CODE_OFF, 16);
code_item co = new code_item();
co.REG_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INSWORD_Sz = byteWalker(_fileImage, currentOffset, 2);
co.OUTS_Sz = byteWalker(_fileImage, currentOffset, 2);
co.TIRES_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INS_COUNT = byteWalker(_fileImage, currentOffset, 4);
List<byte> flare = new List<byte>();
for (int i = 0; i < Convert.ToInt32(co.INS_COUNT, 16); i++)
{
try
{
flare.Add(Convert.ToByte(byteWalker(_fileImage, currentOffset, 1), 16));
}catch (Exception ffd){}
co.INSTRUCTIONS = new List<List<byte>>();
co.INSTRUCTIONS.Add(flare);
//leave the rest for later
_codeRep.Add(co);
}
//Add offset to code as well in the structure
#endregion
return true;
}
}
}
catch (Exception r1) {
return false;
}
Structs Are Excellent Value Types
Structs in C#, just as in other languages, are lightweight instantiable value types. This enables in-class data consolidation for lengthier data types. In C# the syntax is –
[c]
<Access specifier> struct <struct name> {
Constructors;
Fields;
Properties ;
Methods;
}
To give an idea of the struct members that constitute the dex data structures, let us take a look at three of the structures coded.
- The Code_Item Struct:
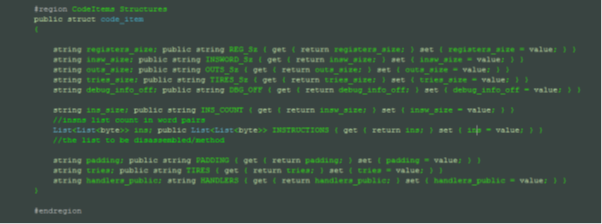
[c]
#region CodeItems Structures
public struct code_item
string registers_size; public string REG_Sz { get { return registers_size; } set { registers_size = value; } }
string insw_size; public string INSWORD_Sz { get { return insw_size; } set { insw_size = value; } }
string outs_size; public string OUTS_Sz { get { return outs_size; } set { outs_size = value; } }
string tries_size; public string TIRES_Sz { get { return tries_size; } set { tries_size = value; } }
string ins_size; public string INS_COUNT { get { return insw_size; } set { insw_size = value; } }
//insns list count in word pairs
List<List<byte>> ins; public List<List<byte>> INSTRUCTIONS { get { return ins; } set { ins = value; } }
string padding; public string PADDING { get { return padding; } set { padding = value; } }
string tries; public string TIRES { get { return tries; } set { tries = value; } }
string handlers_public; string HANDLERS { get { return handlers_public; } set { handlers_public = value; } }
#endregion
[/c]
- THE FULL HEADERS STRUCT (sans struct keyword and braces in snapshot)
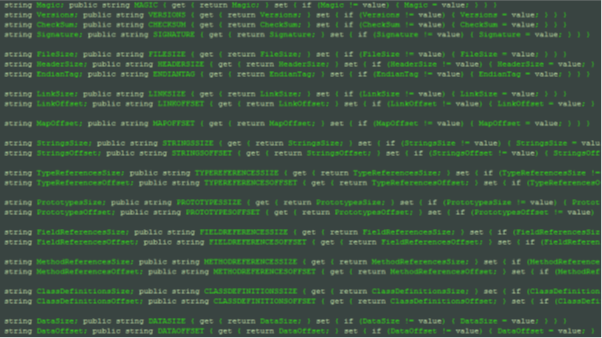
[c]
#region HEADER
public struct Header
{
string Magic; public string MAGIC { get { return Magic; } set { if (Magic != value) { Magic = value; } } }
string Versions; public string VERSIONS { get { return Versions; } set { if (Versions != value) { Versions = value; } } }
string CheckSum; public string CHECKSUM { get { return CheckSum; } set { if (CheckSum != value) { CheckSum = value; } } }
string FileSize; public string FILESIZE { get { return FileSize; } set { if (FileSize != value) { FileSize = value; } } }
string HeaderSize; public string HEADERSIZE { get { return HeaderSize; } set { if (HeaderSize != value) { HeaderSize = value; } } }
string LinkSize; public string LINKSIZE { get { return LinkSize; } set { if (LinkSize != value) { LinkSize = value; } } }
string LinkOffset; public string LINKOFFSET { get { return LinkOffset; } set { if (LinkOffset != value) { LinkOffset = value; } } }
string MapOffset; public string MAPOFFSET { get { return MapOffset; } set { if (MapOffset != value) { MapOffset = value; } } }
string StringsSize; public string STRINGSSIZE { get { return StringsSize; } set { if (StringsSize != value) { StringsSize = value; } } }
string StringsOffset; public string STRINGSOFFSET { get { return StringsOffset; } set { if (StringsOffset != value) { StringsOffset = value; } } }
string TypeReferencesSize; public string TYPEREFERENCESSIZE { get { return TypeReferencesSize; } set { if (TypeReferencesSize != value) { TypeReferencesSize = value; } } }
string TypeReferencesOffset; public string TYPEREFERENCESOFFSET { get { return TypeReferencesOffset; } set { if (TypeReferencesOffset != value) { TypeReferencesOffset = value; } } }
string PrototypesSize; public string PROTOTYPESSIZE { get { return PrototypesSize; } set { if (PrototypesSize != value) { PrototypesSize = value; } } }
string PrototypesOffset; public string PROTOTYPESOFFSET { get { return PrototypesOffset; } set { if (PrototypesOffset != value) { PrototypesOffset = value; } } }
string FieldReferencesSize; public string FIELDREFERENCESSIZE { get { return FieldReferencesSize; } set { if (FieldReferencesSize != value) { FieldReferencesSize = value; } } }
string FieldReferencesOffset; public string FIELDREFERENCESOFFSET { get { return FieldReferencesOffset; } set { if (FieldReferencesOffset != value) { FieldReferencesOffset = value; } } }
string MethodReferencesSize; public string METHODREFERENCESSIZE { get { return MethodReferencesSize; } set { if (MethodReferencesSize != value) { MethodReferencesSize = value; } } }
string MethodReferencesOffset; public string METHODREFERENCESOFFSET { get { return MethodReferencesOffset; } set { if (MethodReferencesOffset != value) { MethodReferencesOffset = value; } } }
string ClassDefinitionsSize; public string CLASSDEFINITIONSSIZE { get { return ClassDefinitionsSize; } set { if (ClassDefinitionsSize != value) { ClassDefinitionsSize = value; } } }
string ClassDefinitionsOffset; public string CLASSDEFINITIONSOFFSET { get { return ClassDefinitionsOffset; } set { if (ClassDefinitionsOffset != value) { ClassDefinitionsOffset = value; } } }
string DataSize; public string DATASIZE { get { return DataSize; } set { if (DataSize != value) { DataSize = value; } } }
string DataOffset; public string DATAOFFSET { get { return DataOffset; } set { if (DataOffset != value) { DataOffset = value; } } }
}
#endregion
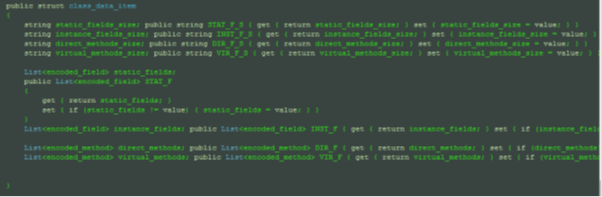
- The Class_Data_Item Struct:
[c]
public struct class_data_item
{
string static_fields_size; public string STAT_F_S { get { return static_fields_size; } set { static_fields_size = value; } }
string instance_fields_size; public string INST_F_S { get { return instance_fields_size; } set { instance_fields_size = value; } }
string direct_methods_size; public string DIR_F_S { get { return direct_methods_size; } set { direct_methods_size = value; } }
List<encoded_field> static_fields;
public List<encoded_field> STAT_F
{
get { return static_fields; }
set { if (static_fields != value) { static_fields = value; } }
}
List<encoded_method> direct_methods; public List<encoded_method> DIR_F { get { return direct_methods; } set { if (direct_methods!=value) direct_methods = value; } }
List<encoded_method> virtual_methods; public List<encoded_method> VIR_F { get { return virtual_methods; } set { if (virtual_methods!=value) virtual_methods = value; } }
}
public struct encoded_field {
string field_idx_diff;
public string FIELD_DFF {
get { return field_idx_diff; }
}
public string ACC_FLG {
get { return access_flags; }
set { access_flags = value; }
}
public struct encoded_method {
string method_idx_diff; public string MET_IDX { get { return method_idx_diff; } set { method_idx_diff = value; } }
string access_flags; public string ACCESS_FLAGS { get { return access_flags; } set { access_flags = value; } }
string code_off;public string CODE_OFF { get { return code_off; } set { code_off = value; } }
}
#endregion
So you keep doing that for all the remaining data types, starting from the header and coding the required sizes and types of the individual fields and the struct in whole.
Filling the Bucket
Parsing thereafter boils down to reading bytes off the locations and filling out the relevant data structure fields in each of the structs.
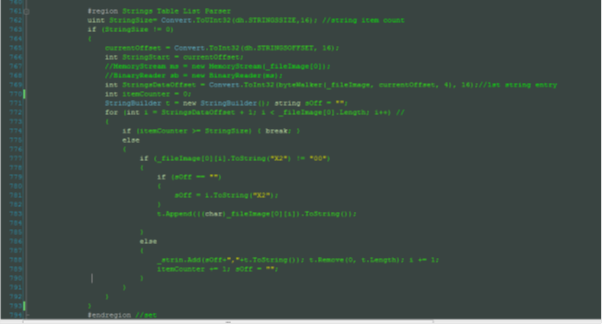
The string parsing code segment later down in the parsing code is shown in the illustration below:
[c]
#region Strings Table List Parser
uint StringSize= Convert.ToUInt32(dh.STRINGSSIZE,16); //string item count
if (StringSize != 0)
{
currentOffset = Convert.ToInt32(dh.STRINGSOFFSET, 16);
int StringStart = currentOffset;
//MemoryStream ms = new MemoryStream(_fileImage[0]);
//BinaryReader sb = new BinaryReader(ms);
int StringsDataOffset = Convert.ToInt32(byteWalker(_fileImage, currentOffset, 4), 16);//1st string entry
StringBuilder t = new StringBuilder(); string sOff = "";
for (int i = StringsDataOffset + 1; i < _fileImage[0].Length; i++) //
{
if (itemCounter >= StringSize) { break; }
else
{
if (_fileImage[0][i].ToString("X2") != "00")
{
if (sOff == "")
{
sOff = i.ToString("X2");
}
}
else
{
_strin.Add(sOff+","+t.ToString()); t.Remove(0, t.Length); i += 1;
itemCounter += 1; sOff = "";
}
}
}
#endregion //set
[/c]
Getting back to the start of the parsing function:
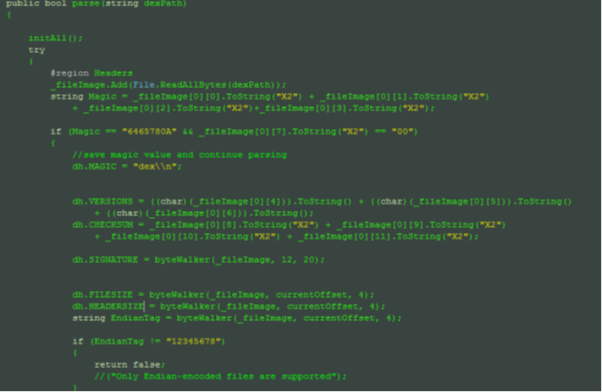
A byte array is turned generic and the file is parsed to a List type. The File.ReadAllBytes(string filePath) method from the System.IO namespace is used to read the entire file to memory and start parsing the byte array. Android files are small in size for the most part and this approach saves the number of IO operations, as the file is read in one shot.
List<byte[]> _fileImage = new List<byte[]>();
Header dh = new Header();
The line above instantiates the Header struct and the parser fills out each of its fields. Notice the use of the byteWalker() function to update and persist to the current offset in the byte array representation of the file.
The process continues digging into each of the structures:
[c]
foreach (class_def_item r in _classDef ){
if (r.ClassData != 0) {
int itemCount=0;int delta=0;
class_data_item ci = new class_data_item();
currentOffset = Convert.ToInt32(r.ClassData);
while (itemCount < 4) //first 4 fields
{
List<List<byte>> g=new List<List<byte>>();
g.Add(ULEB128(_fileImage[0], currentOffset));
delta = g[0].Count;
switch (itemCount){
case 0 : ci.STAT_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 1: ci.INST_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 2:ci.DIR_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
case 3: ci.VIR_F_S=Payload(g[0]);
currentOffset += delta;g.Clear();break;
default :break;
itemCount++;
}
ci.STAT_F = new List<encoded_field>();
for (uint i=0 ;i<Convert.ToUInt32(ci.STAT_F_S,16);i++){
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
currentOffset+=g1[0].Count;g1.Clear();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.ACC_FLG=Payload(g1[0]);
ci.STAT_F.Add(ef); //store the fields list for this class_data_item
}
ci.INST_F = new List<encoded_field>();
for (uint i=0 ;i<Convert.ToUInt32(ci.INST_F_S,16);i++){
encoded_field ef=new encoded_field();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.FIELD_DFF=Payload(g1[0]);
currentOffset+=g1[0].Count;g1.Clear();
g1.Add(ULEB128(_fileImage[0],currentOffset));
ef.ACC_FLG=Payload(g1[0]);
ci.INST_F.Add(ef);//store the instance lists
}
ci.DIR_F = new List<encoded_method>();
for (uint i=0 ;i<Convert.ToUInt32(ci.DIR_F_S,16);i++){
encoded_method em=new encoded_method();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.MET_IDX=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.ACCESS_FLAGS=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.CODE_OFF=Payload(g1[0]);
ci.DIR_F.Add(em);
}
ci.VIR_F = new List<encoded_method>();
for (uint i=0 ;i<Convert.ToUInt32(ci.VIR_F_S,16);i++){
encoded_method em=new encoded_method();
List<List<byte>> g1=new List<List<byte>>();
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.MET_IDX=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.ACCESS_FLAGS=Payload(g1[0]);
g1.Add(ULEB128(_fileImage[0],currentOffset));
em.CODE_OFF=Payload(g1[0]);
ci.VIR_F.Add(em);
}
_classDataItem.Add(ci); //store the class_data_items
}
[/c]
The excerpts above give an idea of the rather quick and dirty, though structured, way of filling a memory structure. Moving further in, finally we get to the code offsets we need to parse from to get the opcodes. If you recollect the sub-references path this is exactly what we have in mind:
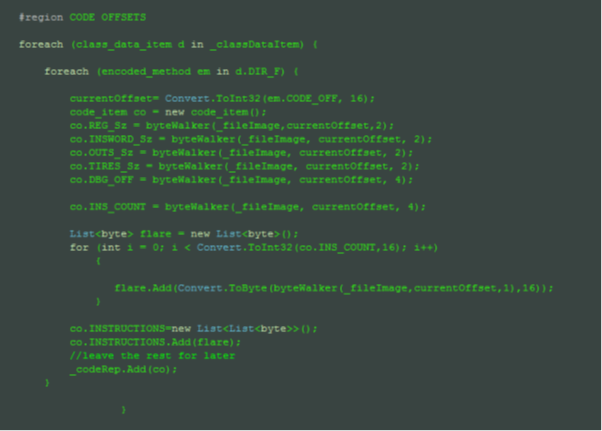
[c]
#region CODE OFFSETS
foreach (class_data_item d in _classDataItem) {
foreach (encoded_method em in d.DIR_F) {
currentOffset= Convert.ToInt32(em.CODE_OFF, 16);
code_item co = new code_item();
co.REG_Sz = byteWalker(_fileImage,currentOffset,2);
co.INSWORD_Sz = byteWalker(_fileImage, currentOffset, 2);
co.OUTS_Sz = byteWalker(_fileImage, currentOffset, 2);
co.TIRES_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INS_COUNT = byteWalker(_fileImage, currentOffset, 4);
List<byte> flare = new List<byte>();
for (int i = 0; i < Convert.ToInt32(co.INS_COUNT,16); i++)
flare.Add(Convert.ToByte(byteWalker(_fileImage,currentOffset,1),16));
}
co.INSTRUCTIONS=new List<List<byte>>();
co.INSTRUCTIONS.Add(flare);
//leave the rest for later
_codeRep.Add(co);
}
foreach (class_data_item d in _classDataItem)
{
foreach (encoded_method em in d.VIR_F)
{
currentOffset = Convert.ToInt32(em.CODE_OFF, 16);
code_item co = new code_item();
co.REG_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INSWORD_Sz = byteWalker(_fileImage, currentOffset, 2);
co.OUTS_Sz = byteWalker(_fileImage, currentOffset, 2);
co.TIRES_Sz = byteWalker(_fileImage, currentOffset, 2);
co.INS_COUNT = byteWalker(_fileImage, currentOffset, 4);
List<byte> flare = new List<byte>();
for (int i = 0; i < Convert.ToInt32(co.INS_COUNT, 16); i++)
{
try
{
flare.Add(Convert.ToByte(byteWalker(_fileImage, currentOffset, 1), 16));
}catch (Exception ffd){}
co.INSTRUCTIONS = new List<List<byte>>();
co.INSTRUCTIONS.Add(flare);
//leave the rest for later
_codeRep.Add(co);
}
//Add offset to code as well in the structure
#endregion
[/c]
The first foreach loop set was for digging into the DIRECT functions, while the second set of foreach loops digs into VIRTUAL functions.
All code instructions are saved in the _codeRep.Add() list, which acts as a repository for the insns [].
At this point the dex file parsing is complete.
Now each of the struct instances is exposed through properties that return the instances to another class. These instances can be further queried using the '.' 'dot operator syntax' to get the individual types for processing further. Now the disassemble code in another class can be fed the opcode lists directly. In keeping with the dex format design, the disassembler will also be have to fed the data from other types and segments as well, so that the code cross-referencing can be done precisely. That can be taken care of in the disassemble class J
CONCLUSION
Take your hacking to the next level
Learn how to pentest and be an ethical hacker with expert-guided training, or learn more about the world of ethical hacking.
We have taken a look at the process of coding a parser for the binary format—DEX in C# (OOP). If you find any other binary format you wish to parse like PE format, you know how you might approach it. For those of us looking for a bit of challenge try doing the same in a functional programming language like Haskell. The process can be interesting and the approach is quite different from OOP.


- 12 pre-built training plans
- Employer-requested skills
- Personalized, hands-on training
In this series
- Writing Your Own Parser
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
