Fuzzing: Mutation vs. generation

Many of you have undoubtedly come across the word "Fuzzing" and wondered about it. But if you have ever tried modifying some parameter; some sort of input/arguments; tried deviating it from the normal expected input – then you have indeed tried fuzzing, all by yourself.
Learn Threat Modeling
The standard definition of Fuzzing (according to the Standard Glossary of Software Engineering Terminology, IEEE) is
"The degree to which a system or component can function correctly in the presence of invalid inputs or stressful environmental conditions."
Fuzzing (or "fuzz testing") is basically nothing more than a software testing technique used to uncover a variety of issues, among them: coding errors; security vulnerabilities like Cross Site Scripting; Buffer Overflow; Denial of Service, and so forth, using unexpected, malformed, random data (called "fuzz") as program inputs. You are, in effect, trying to crash the program or make it behave unexpectedly.
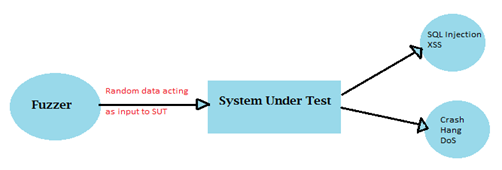
Fuzzing history
Fuzzing can be traced back to the University of Wisconsin in 1988. There, Professor Barton Miller gave a class project titled "Operating System Utility Program Reliability - The Fuzz Generator." It was the first – and simplest – form of fuzzing, and included sending a stream of random bits to UNIX programs by the use of a command line fuzzer.
In a response by email when asked about the origins of the term "fuzz," Professor Miller replied:
"The original work was inspired by being logged on to a modem during a storm with lots of line noise. And the line noise was generating junk characters that seemingly were causing programs to crash. The noise suggested the term 'fuzz'".
Even though the term was coined by Barton Miller, early examples of fuzzing include "The
Monkey." It was a small desk accessory that engaged the journaling hooks to feed random events to the current application. As a result, the Macintosh seemed to be operated by an incredibly fast, somewhat angry monkey, banging away at the mouse and keyboard, generating clicks and drags in random positions with wild abandon.
In 1998, the PROTOS project at University of Oulu was proposed for the purpose of enabling the software industry themselves to find security critical problems, using new model-based test automation techniques, as well as other next generation fuzzing techniques. Later (in 2001), Codenomicon (another network protocol fuzz testing solution) was founded, based on PROTOS. With this, the Fuzzers just kept on improving in technology and methodology, encompassing a new generation of fuzzing frameworks, including SPIKE, PeachFuzzer etc.
Why fuzzing
When test cases are defined for any product, they might be defined by considering how they are designed to behave (as well as how they shouldn't behave). But within these criteria there is always an undefined area beyond the imagination of test developer. The challenge is to explore that undefined region and the companion here is fuzzing. The main purpose of fuzzing is not to test the correct functionality of the product/program as such, but to explore and test that undefined area.
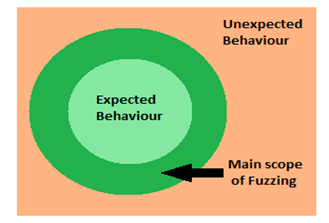
Classification/categorisation:-
Enormous classifications exist for fuzzing depending on attack vectors, fuzzing targets, fuzzing method, and so forth. Fuzzing targets for an application include file formats, network protocols, command-line args, environment variables, web applications and many others.
The first classification which we will consider is the way test cases are generated; or in other words, how the application is altered if fuzzed. There are two approaches here: mutation and generation, explained below.
Mutation vs. generation (dumb vs. intelligent)
Mutation (dumb fuzzers)
Here, it's all about mutating the existing input values (blindly). That's why it is known as "dumb" fuzzers, as in lacking understanding of the format/structure of the data. One example can be just replacing/appending a random section of data.
Example: Bit Flipping is the one of the techniques used in the mutation, wherein the bits are flipped in some sequence or randomly.

Similarly, we can append some string at the end of the existing input.
Bit flipping with ZZUF (mutation):
ZZUF
One of the most common fuzzers available for bit flipping is zzuf. It is a transparent application input fuzzer, whose purpose is to find bugs in applications by corrupting their user-contributed data, changing the random-bits in the input.
ZZUF architecture consists of two parts: the first being zzuf executable; the second is Libzzuf shared library file. Once the zzuf executable is run, it first reads the command line fuzzing options, then saves these in the internal environment. Libzzuf is preloaded into the process, executed and then reads the saved fuzzing options from the environment. In order to intercept file and network operations, signal handlers and memory allocations, Libzzuf diverts and re-implements the functions, which can sometimes be private C library symbols. Hence; all the diverted calls go through Libzzuf.
Consider the example of fuzzing an input file with zzuf and cat (Linux utility).
Screen 1: It shows the input file "fuzz.txt" which we will use as the input to zzuf utility.
Screen 2: With zzuf, we can change the amount of bits we want to fuzz and can specify it with –r flag. As shown, 0.002 means fuzz 0.2% of the bits and 0.01 means fuzz 1% of the bits.
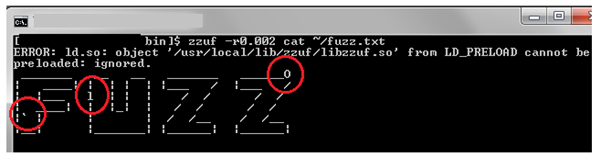
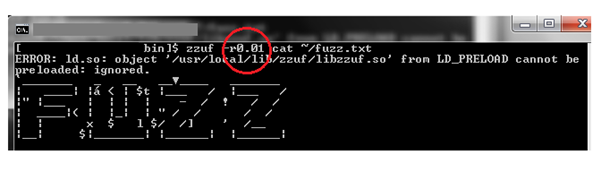
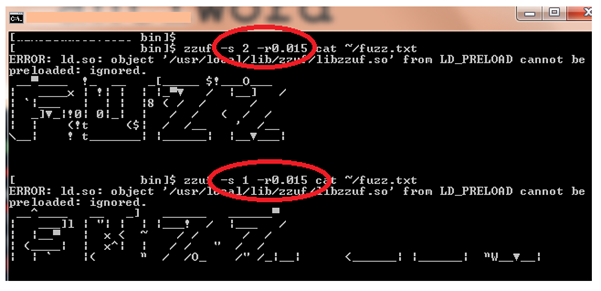
Screen 3: With the same fuzzing ratio, zzuf behaviour is reproducible. Sometimes, we may want to change the fuzzed output without changing the fuzzing ratio; in that case, zzuf provides another command line option specified by –s flag, called the seed flag. This sets the initial random seed used internally by zzuf random number generator and hence, even though the random ratio is same, the fuzzed output is different.
Generation (intelligent fuzzer)
In contrast to Dumb Fuzzers, here an understanding of the file format / protocol is very important. It's about "generating" the inputs from the scratch based on the specification/format.
Intelligent fuzzing with Peach fuzzer:
Peach fuzzer
Peach Fuzzer is a smart fuzzer with both the generation and mutation capabilities. It works by creating PeachPit files, which are the XML files containing the complete information about the data structure, type information and the relationship of the data.
Peach works on several components: among them, Data Modelling; State Modelling; Publisher; Agents; Monitor, and Loggers, and so forth. Here, in this section, we will be discussing the modelling part, mainly because it is related to the intelligent fuzzer. Later, in the second part of fuzzing, we will be discussing other components of Peach Fuzzer as well.
Let's discuss the creation of a sample PeachPIT file for HTTP Protocol. As an example:
Peach focuses heavily on both the data modelling and state modelling. The level of detail that is put into these models serves to illustrate the striking difference between a dumb Peach Fuzzer and a smart one.
Data modelling
Peach Pit files will contain at least one data model. Data Models define the structure of a data block by specifying additional child elements, such as Number and String.
[sourcecode language="xml"]
[/sourcecode]
Complex protocols are split into parts: each part with its own data model for reuse. A data model can then further be split into Blocks. Also, if a reference (ref attribute) is supplied, the contents of the reference are copied to create the base of the new data model. Any child elements in the data model will override elements that already exist with the same name.
[sourcecode language="xml"]
<!-- Indicate a relation between this field and the "Body" field. -->
[/sourcecode]
Here, it will override both the String definition and will be equivalent to :-
[sourcecode language="xml"]
<!-- Indicate a relation between this field and the "Body" field. -->
[/sourcecode]
We can also see the relation attribute which is used to model the relationship of different data. So in this case, the value is equivalent to the size of the Body element which is described as :-
[sourcecode language="xml"]
[/sourcecode]
Sample data model for HTTP Protocol would be:-

State Modelling
A State Model consists of at least one state and one model. In the case of multiple states , initialState attribute determines the first State of the model.
[sourcecode language="xml"]
[/sourcecode]
Here "<Action>" performs various actions in the state model, such as sending output to the publisher or reading input via publisher specified in some data model, and so forth. In our case, there is only one State and one Action which would be performed on the DataModel HttpRequest. Now, Action has an optional child element – "Data" – which is used to create and load a default set of data into the data models.
[sourcecode language="xml"]
[/sourcecode]
This would create a set of default values for any data model used and would override the default values, if any. Similar to the data model references, we have references in Data also .
[sourcecode language="xml"]
[/sourcecode]
Sample State Model and Data for HTTP would be :-

Now, after data modelling and state modelling is completed, our aim is to run the fuzzer against web server. The test element configures a specific fuzzing test that combines a state model with a publisher. (We will discuss more about publisher later). The publisher here is basically targeting our requests to the web server on the localhost.
[sourcecode language="xml"]
<!-- Target a local web server on port 80 -->
[/sourcecode]
Similarly , another test :-
[sourcecode language="xml"]
[/sourcecode]
Finally, we need a run element to group all the elements together.
[sourcecode language="xml"]
<!-- The set of tests to run -->
[/sourcecode]
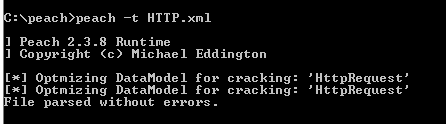
That completes the creation of basic PeachPIT file and we will run it with Peach Fuzzer.
Screen 1: -t flag is to perform the parsing of the Peach XML File.
Screen 2: -1 option is to run only 1 iteration and debug enables the debug messages.
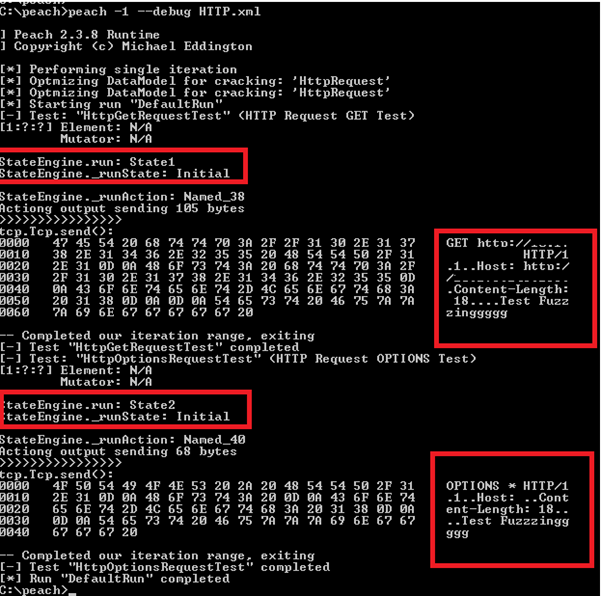
With configuration of loggers and agent , we can track the progress and the faults .
Comparison
Even though the mutation approach is easier than the generation based approach (because it doesn't require understanding of the protocol), generation is better because it submits valid combinations of input and has better code coverage and code paths. Even though the generation based approach takes more time to do, it is considered to be a more thorough process.
Advantages of fuzzing
Fuzzing is a random way of testing, using an approach that enables it to find the bugs which are impossible to find in the defined testing or approach-based testing. It will detect exploitable issues of real value, and with hardly any assumptions/presumptions made before starting the process. It's very easy and quick to setup, and once the setup is done, easy to repeat it for regression.
Limitations of fuzzing
Fuzzing effectively locates simple bugs. It is valuable when attacking a black box system, but carries an inherent limitation, in that there is hardly any information to check the impact of the fuzzing. Writing a protocol specification or file format specification is a tedious task. The random approach has its advantages, but on the downside, it does lag behind in finding the boundary value issues.
Part 2 is about Application and File Fuzzing and is now published here: /application-and-file-fuzzing/
Learn Secure Coding Fundamentals
Sources

Learn SCADA Security Fundamentals
Get hands-on experience around ICS and their environments, devices, regulatory standards and more. What you'll learn:
- Access controls
- Common cyber threats
- Process control networks
- ICS protocol features
- And more
In this series
- Fuzzing: Mutation vs. generation
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Phishing simulations & training
Unlock pricing and see how Infosec IQ can help you empower employees with 2,000+ security awareness resources to:
- Reduce security events
- Reinforce cyber secure behaviors
- Strengthen cybersecurity culture at your organization

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.


Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
