Linear sweep vs recursive disassembling algorithm

We know that there are two ways of disassembling a binary executable into its assembler instructions. The first technique is linear sweep algorithm and the second is recursive disassembling. In this article, we'll describe both techniques and take a look at an example of each, then we'll briefly discuss how they can be used for anti-reversing.
Learn Web Server Protection
Linear sweep
When using the linear sweep algorithm, we're going through the .text sections of the executable and disassembling everything sequentially. It starts with the first byte in the code section and proceeds by decoding each byte, including any intermediate data byte, as code, until an illegal instruction is encountered [1]. This makes the algorithm very simple, but also susceptible to any mistakes intentionally left in the code to derail the linear sweep algorithm from its path. The most common linear sweep disassemblers are objdump, WinDbg and SoftICE.
Let's take a look at the following example, which is written in C++ in Visual Studio:
[cpp]
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
__asm {
A:
jmp B
_emit 0x0f
B:
mov eax, 0x10
push eax
call C
C:
}
/* wait */
getchar();
return 0;
}
[/cpp]
If we compile and run the program, a notification dialog such as the one seen on the picture below, will be displayed:

This is because we're pushing something onto the stack (the "push eax" instruction), so when the function returns, the EIP and ESP cannot be properly restored, since we're now trying to load a different value in the ESP register when returning (because of an additional push instruction). I won't describe this here in detail, because it's really not important for the purpose of this exercise. What's important is how different disassemblers disassemble the executable. Let's first load the compiled executable in Olly disassembler, which produces the result that can be seen on the picture below:

We can see that Olly has properly disassembled the executable. First, there is the jmp short 00411A11 call that corresponds to our "jmp B" instruction in C++ source code. Then there is one byte of data that Olly has correctly assigned the "DB 0F" instruction. If we place a breakpoint on the "jmp short 00411A11" instruction and run the program, the program execution will hit that breakpoint and pause the execution. If we then press the step into button (F7 in Olly), the execution will of course jump to the 0x00411A11 instruction right after the "DB 0F" instruction, which will never be executed. This proves that Olly can correctly disassemble the executable and execute all the instructions the way they should be executed.
Let's take a look at how successful Ida is at disassembling the above code. We can see the disassembled piece of code on the picture below:

Cool, we can see that Ida was quite successful at the disassembly and it also preserved the actual label names that we're using for jumping around the executable. We can also see that Ida has correctly identified the data inside the instructions at address 0x00411A10 and it automatically placed the comments around it to make it stand out as a non-used instruction, which is correct since it's a data instruction and shouldn't be executed. Since Olly and Ida are using the recursive traversal approach to disassembly, they have been able to correctly disassemble the executable. But what if we load the executable into WinDbg and observe our interesting piece of code? We can see the disassembled code on the picture below.

We used the following commands in WinDbg to get the result that we needed:
[plain]
0:000> bp 0x411A0E
0:000> g
0:000> u 0x00411A0E
linear_sweep+0x11a0e:
00411a0e eb01 jmp linear_sweep+0x11a11 (00411a11)
00411a10 0fb810000000 jmpe linear_sweep+0x11a26 (00411a26)
00411a16 50 push eax
00411a17 e800000000 call linear_sweep+0x11a1c (00411a1c)
00411a1c 8bf4 mov esi,esp
00411a1e ff15cc824100 call dword ptr [linear_sweep+0x182cc (004182cc)]
00411a24 3bf4 cmp esi,esp
00411a26 e810f7ffff call linear_sweep+0x1113b (0041113b)
[/plain]
We can see that WinDbg wasn't able to correctly disassemble the code. At first it has correctly disassembled the jmp instruction, but all of the subsequent instructions are not correct, which is because of the "DB 0F" data instruction. Since WinDbg uses a linear sweep algorithm to disassemble the executable, it tried to use the "DB 0F" instruction as part of the code instructions, which is incorrect and disassembles into incorrect instruction. Not to mention that after that, the offsets for all the other instructions are wrong and all the instructions following that data instruction are also incorrectly disassembled.
We've just seen an example that fools the linear sweep algorithm, but not a recursive traversal algorithm. The next example we'll look at will instead be able to fool the recursive traversal algorithm.
Recursive traversal
This technique is far less susceptible to mistakes than the linear sweep algorithm, which is because the code isn't disassembled in a linear way, but rather the jump and branch instructions are followed. So basically, we're doing a linear sweep algorithm, except when we stumble upon the branch/jump instructions, we follow it and again start doing the linear sweep algorithm. The most common recursive traversal disassemblers are Olly and Ida.
Here we'll take a look at an example of the code that can fool the linear sweep algorithm as well as recursive traversal algorithm. Let's take a look at the following program that is written in C++ and taken from [2] (the difference is that the full code of the program is actually given and not only the assembly part):
[cpp]
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
__asm {
A:
mov eax, 2
cmp eax, 2
je B
_emit 0xf
B:
mov eax, 10
push eax
call C
C:
}
/* wait */
getchar();
return 0;
}
[/cpp]
We can see that we're first moving the variable 2 into the register eax and then comparing the value 2 with the value stored in register eax. The values are of course equal, since we previously saved the same value into register eax. This is why the je instruction will always be evaluated to true and why the jump will always happen.
Let's now take a look at how the various tools disassemble the above code and if they can do it correctly. Let's first take a look of how Olly can disassemble the above code. We can see the disassembled version of the code below:

We can quickly see that Olly disassembled all the instructions correctly. Let's also take a look at how Ida disassembles the interesting code:

Clearly, Ida was also able to correctly disassemble the code in question. This proves that despite trying to confuse the Olly and Ida disassemblers, they are nevertheless able to reproduce the correct disassembled code. However, the WinDbg disassembler is once again wrong, as we can see on the picture below:

Let's also take a look at the more complicated example presented below [2]:
[cpp]
#include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
__asm {
A:
mov eax, 2
cmp eax, 3
je B
mov eax, C
jmp eax
B:
_emit 0xf
C:
mov eax, 10
push eax
call D
D:
}
/* wait */
getchar();
return 0;
}
[/cpp]
Olly disassembles the above code as presented on the picture below:

And then Ida disassembles the code the same as Olly, as presented on the picture below:
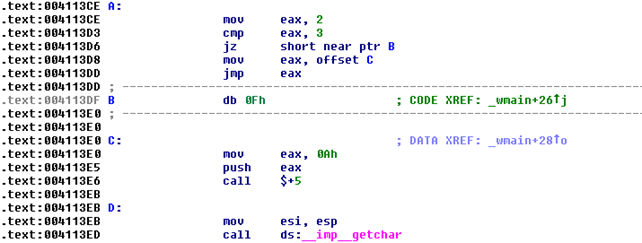
Both, Olly and Ida again disassembled the code correctly, so they are not falling for the tricks we've inputted into the source code above. If we continue to complicate things and make the executable harder for the disassembler to analyze, then there exists a greater possibility that the disassemblers will present an invalid assembly code back to us. The problem exists because the disassembler can't actually run the code in order to produce the right disassembly instructions, but must analyze it without running the code.
Imagine what could happen if the debugger would first run the code in order to present the disassembled instructions: it could unintentionally run some malicious code that could possibly infect our computer before actually presenting the assembly instructions to us. This isn't acceptable, which is why the debuggers can't run the code when they are trying to figure out the right assembly instructions. This is the reason why we can use special tricks that the disassemblers can't easily swallow to try to mess them up, which can result in incorrectly disassembled assembly code.
Disassembly challenges
How can the previously described techniques be used as an anti-reversing technique to harden the reverse engineering of an executable? Some architectures use variable length instructions so the disassemblers can be tricked into disassembling the operations and data the wrong way. This also has another disadvantage in that the rest of the code from that single incorrectly disassembled byte can cause the whole code to be disassembled incorrectly.
There are six points at [1] that can be used to trick the disassembler into making a mistake when disassembling the code, which are presented below (summarized after [1]):
1. Data embedded in the code regions: This is a real problem for linear sweep disassemblers because we can't simply distinguish the code from data in a binary file. Because the linear sweep algorithm decodes each byte as code as long as it looks like a legitimate code byte, it ends up interpreting many data bytes as instructions [1].
2. Variable instruction size: Because the x86 instruction set allows variable instruction size, the problem with linearly disassembling the code is even bigger.
3. Indirect branch instructions: If the program uses indirect branch instructions like "call eax" or "jmp dword [esp+xx]," even the recursive traversal algorithm has trouble disassembling the code with 100% accuracy.
4. Functions without explicit CALL sites within the executable's code segment: Because there is no identifiable call to these funtions, we can't discover them through control flow analysis and may be misclassified as data.
5. Position independent code (PIC) sequences.
6. Hand crafted assembly code.
The six points above present the tricks that we can use to fool the disassemblers from correctly disassembling the executable.
Conclusion
We've presented the linear sweep and recursive traversal algorithms that can be used to disassemble an executable into its assembly instructions. We've taken a look at a few tricks that we can use to fool either the linear sweep or recursive traversal algorithms into presenting the wrong assembly code.
Keep in mind that we can do this because the debuggers can't actually run the code to observe what really happens when the executable in being executed. Because of the tricks we've put into the executable code, the disassemblers can be fooled into thinking and presenting the wrong assembly instructions to the user. This can increase the time the reverse engineer needs to actually figure out what the program does, but can't stop the reversers from actually reverse engineering the executable. We can manually tell Olly and Ida that a data byte is located at some address and is not a part of the code instructions, which would tell Olly or Ida to rescan the code, take into account the new data byte, analyze the executable, and then present the right assembly instructions.
Learn Network Forensics
Sources
- Disassembly Challenges
- Eldad Eilam, Secrets of reverse engineering.
- Chris Eagle, The IDA Pro Book: The unofficial guide to the world's most popular disassembler.


CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.


Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
