Analyzing malicious JavaScript

Nowadays there are various threats in the wild that want to get malware installed on victim operating systems. Most of them use some kind of social engineering bundled together with some means to actually execute the malicious code, like JavaScript, malicious PDF documents, malicious Microsoft Office documents, etc.

Become a certified reverse engineer!
Of course, if we want the malicious code to execute, we must exploit some kind of vulnerability that exists in web browsers (if we're propagating malware with JavaScript), Microsoft Word (if we're propagating malware with .doc documents), Adobe PDF Reader (if we're propagating malware with .pdf files), etc.
All in all, we need to know that vulnerabilities are being exploited in all programs because of the malicious input data (all programs accept some kind of input data): web browsers accept web sites as input data, Microsoft Word accepts .doc documents as input, Adobe PDF Reader accepts .pdf files as input data, etc. Therefore, if we can construct a malicious input data that exploits the vulnerability present in some of these programs, we can execute arbitrary data.
Here we'll take a look at the malicious JavaScript code that tries to execute arbitrary instructions on the target operating system.
JavaScript
JavaScript is pretty important when analyzing it, because we're spending considerate amount of our time in web browsers. And since web browsers understand, accept and execute JavaScript, we can feed a URI to the victim and wait for him/her to click on it. Upon clicking on the URI, we can send arbitrary malicious JavaScript to the victim, which will be executed in the web browser. We're not limited to JavaScript only; we can use any kind of language that web browsers understand, but we're using JavaScript because we can do pretty much anything with it.
If we're using JavaScript, we're not limited to the web browsers only. We can embed malicious JavaScript in any kind of input data being passed to the application that understands it. Thus, we can embed JavaScript into PDF document, SWF files, etc.
Attackers will often obfuscate the JavaScript embedded in any kind of document to harden the analysis of it. In such cases we can use deobfuscator to beautify the JavaScript code in order to make it more readable and thus easier to understand.
Spidermonkey is a stand-alone C library implementation of JavaScript interpreter. We can use it to analyze any JavaScript code, which is far safer than executing it directly in a web browser.
De-obfuscating JavaScript manually
Usually, an attacker obfuscates their JavaScript code so it isn't readable anymore. An example of such a code can be seen below:
[jscript]<script>
function deobfuscate(input) {
// deobfuscation code
}
eval(deobfuscate('23230433239 … '));
</script>
[/jscript]
The code doesn't actually do anything, but we can see what the code is doing: it's passing the integer argument to the deobfuscate() function, which deobfuscates the integers into real JavaScript code and evaluates and executes it. It's evident that we need to take a hold of the deobfuscated JavaScript hold that is executed every time the page is loaded, but how?
The answer is by redefining the eval function, which becomes print function. This effectively prints the deobfuscated code rather than executes it. To do that, we need to copy the above code into a separate file (just the JavaScript code without the starting and ending <script> tag) and append the line below at the top of that file:
[jscript]
eval = print
[/jscript]
This redefines the eval function into print function. After that we can open that file with a web browser, but a better way is using the js command that comes with SpiderMonkey like below:
[bash]
# js example.js
[/bash]
The SpiderMonkey will then execute the deobfuscate() function and print the result on the screen instead of executing it. Now we can start analyzing the deobfuscated JavaScript code and take a look at what the attacker was trying to achieve.
De-obfuscating JavaScript with Jsunpack
Jsunpack can be used to de-obfuscate obfuscated JavaScript code automatically. It is a web application in which we can directly copy the obfuscated JavaScript code. The web application then analyzes the code and presents it back to us. The Jsunpack web application can be seen in the picture below:
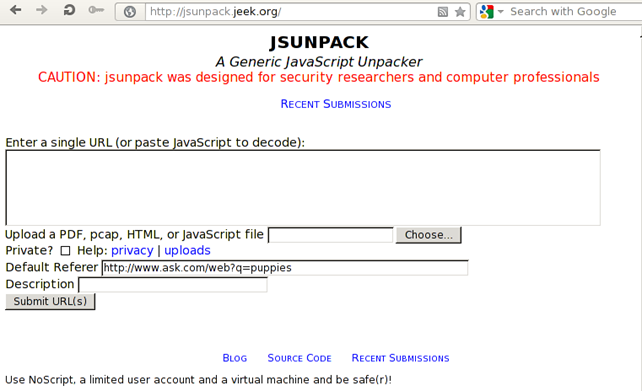
There are multiple input elements that the web applications accepts. We can paste the JavaScript code directly to the input box, we can provide an URL to the webpage that uses obfuscated JavaScript, we can even upload the PDF, PCAP, SWF, HTML or JavaScript files that will be analyzed automatically. The private checkbox option can be enabled if we don't want the code to be released to the public and be made generally available. The privacy link right beside it presents us with the full explanation of that option, which can be seen on the picture below:

At the bottom of the page there are also three links. The first one is named "Blog" and points to the Jsunpack blog. The second one is named "Source Code" and points to the Google Code website of the Jsunpack-n tool. The third link is named "Recent Submissions" and points to the obfuscated malicious JavaScript code that was recently submitted; this is also presented in the picture below:
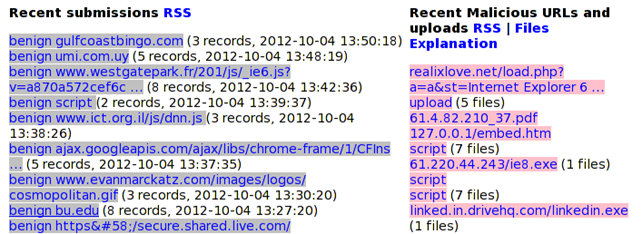
On the left side are recent submissions that don't contain any malicious JavaScript code and on the right side are malicious JavaScript code submissions. If we click on one of the examples, there will be a detailed description of the obfuscated JavaScript code with a download link, which we can use to download a zip archive that contains the malicious JavaScript code.
Let's download that PDF document, referenced as 61.4.82.210_37.pdf in the malicious uploads. Let's download the zip archive, which contains the file as presented below:
The first thing we want to do is to categorize the file based on the header information. We can do that with the file command, which says that the file is a PDF document:
[bash]
# file c41f10c79ccea7432987a9d7050604a3eb47
c41f10c79ccea7432987a9d7050604a3eb47: PDF document, version 1.2
[/bash]
After that it's time to download the jsunpack-n program, which emulates browser functionality when visiting a URL. It can detect malicious code that can be used to exploit a web browser and browser plugins. After we've downloaded the tool and installed all dependencies (as noted in the INSTALL file), we can run jsunpack-n, which has the options presented below:
[bash]
# ./jsunpackn.py -h
Usage:
./jsunpackn.py [fileName]
./jsunpackn.py -i [interfaceName]
jsunpack-network version 0.3.2c (beta)
[warning] pynids is disabled, while you cannot process pcap files or a network interface, you can still process JavaScript/HTML files
Options:
-h, --help show this help message and exit
-t TIMEOUT, --timeout=TIMEOUT
limit on number of seconds to evaluate JavaScript
-r REDOEVALTIME, --redoEvalLimit=REDOEVALTIME
maximium evaluation time to allow processing of
alternative version strings
-m MAXRUNTIME, --maxRunTime=MAXRUNTIME
maximum running time (seconds; cumulative total). If
exceeded, raise an alert (default: no limit)
-f, --fast-evaluation
disables (multiversion HTML,shellcode XOR) to improve
performance
-u URLFETCH, --urlFetch=URLFETCH
actively fetch specified URL (for fully active fetch
use with -a)
-d OUTDIR, --destination-directory=OUTDIR
output directory for all suspicious/malicious content
-c CONFIGFILE, --config=CONFIGFILE
configuration filepath (default options.config)
-s, --save-all save ALL original streams/files in output dir
-e, --save-exes save ALL executable files in output dir
-a, --active actively fetch URLs (only for use with pcap/file/url
as input)
-p PROXY, --proxy=PROXY
use a random proxy from this list (comma separated)
-P CURRENTPROXY, --currentproxy=CURRENTPROXY
use this proxy and ignore proxy list from --proxy
-q, --quiet limited output to stdout
-v, --verbose verbose mode displays status for all files and
decoding stages, without this option reports only
detection
-V, --very-verbose shows all decoding errors (noisy)
-g GRAPHFILE, --graph-urlfile=GRAPHFILE
filename for URL relationship graph, 60 URLs maximium
due to library limitations
-i INTERFACE, --interface=INTERFACE
live capture mode, use at your own risk (example eth0)
-D, --debug (experimental) debugging option, do not delete
temporary files
-J, --javascript-decode-disable
(experimental) dont decode anything, if you want to
just use the original contents
[/bash]
Now we can run jsunpack-n on our malicious PDF file as follows:
[bash]
# ./jsunpackn.py c41f10c79ccea7432987a9d7050604a3eb47
[suspicious:5] [PDF] c41f10c79ccea7432987a9d7050604a3eb47
suspicious: PDFobfuscation detected Collab[
file: decoding_0c3be4288226f0bd341d8692d02a42652e9109e1: 78750 bytes
file: original_f21cc41f10c79ccea7432987a9d7050604a3eb47: 13565 bytes
[/bash]
We can see that the original PDF file was written at a location temp/files/ original_f21cc41f10c79ccea7432987a9d7050604a3eb47, while the decoded JavaScript was written to temp/files/decoding_0c3be4288226f0bd341d8692d02a42652e9109e1. The suspicious function uses a string Collab and is presented below:
[plain]
function S7aL(u713,u714){Collab['u0067u0065u0074u0049u0063u006fu006e'](u714+u713);}
[/plain]
If we translate the Unicode encoding into ASCII we get the following JavaScript code:
[plain]
function S7aL(a,b){ Collab['getIcon'](b,a); }
[/plain]
But why is this suspicious? It's only calling the getIcon() method. We can quickly get an answer to that if we Google a bit. There's a remote code execution vulnerability in Acrobat Reader when calling Collab 'getIcon()' as can be seen here. This can be also seen in the picture below:
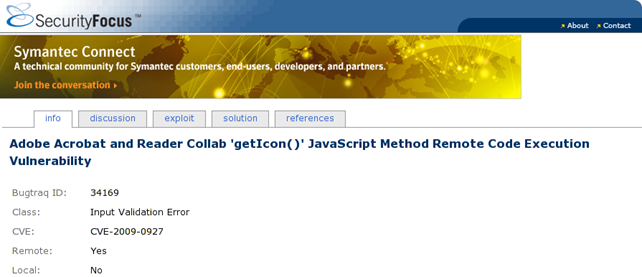
It's indeed the right choice to flag this PDF document as malicious.
There are also various other options we can use when running jsunpack-n. One interesting option is the --timeout option that specifies the number of seconds for evaluation of JavaScript, which is useful if JavaScript is using heap spraying technique. The default timeout is 30 seconds, after which, if processing is still not finished, the evaluation is terminated and the results gathered so far are presented. If we run the above analysis with a verbose flag set, we get the output below:
[plain]
# ./jsunpackn.py -V c41f10c79ccea7432987a9d7050604a3eb47
[malicious:10] [PDF] c41f10c79ccea7432987a9d7050604a3eb47
info: [decodingLevel=0] JavaScript in PDF 78663 bytes, with 87 bytes headers
suspicious: PDFobfuscation detected Collab[
info: [decodingLevel=1] found JavaScript
error: undefined variable DDGfx
info: Decoding option app.viewerVersion=9.1, 0 bytes
info: Decoding option app.viewerVersion=8.0 and app.viewerVersion=7.0, 56 bytes
info: Decoding option app.viewerVersion=, 42 bytes
malicious: Utilprintf CVE-2008-2992 detected
malicious: Alert detected //alert CVE-2008-2992 util.printf length (7,undefined)
info: [2] no JavaScript
info: file: saved ../c41f/c41f10c79ccea7432987a9d7050604a3eb47 to (./temp/files/original_f21cc41f10c79ccea7432987a9d7050604a3eb47)
file: decoding_0c3be4288226f0bd341d8692d02a42652e9109e1: 78750 bytes
file: decoding_9ff1f85b784f0684a5ddae6d96d0c9da5302fab1: 56 bytes
file: original_f21cc41f10c79ccea7432987a9d7050604a3eb47: 13565 bytes
[/plain]
Let's compare the results with the online version of the jsunpack. The online analysis of the same PDF document can be seen in the picture below:
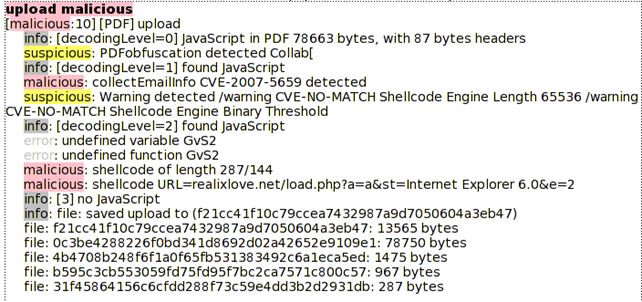
We can see that the detected vulnerabilities are not the same if we analyze the file with jsunpack-n command line tool and jsunpack online version. Why is that? It's simply because the online version uses the -f argument, which improves performance by evaluating the PDF document with a limited range of PDF Reader version numbers. If we add that option to the jsunpack command line, we get the same output as we can see below:
[plain]
# ./jsunpackn.py -V -f c41f10c79ccea7432987a9d7050604a3eb47
[malicious:10] [PDF] c41f10c79ccea7432987a9d7050604a3eb47
info: [decodingLevel=0] JavaScript in PDF 78663 bytes, with 87 bytes headers
suspicious: PDFobfuscation detected Collab[
info: [decodingLevel=1] found JavaScript
error: undefined variable DDGfx
info: Decoding option app.viewerVersion=9.1, 0 bytes
info: Decoding option app.viewerVersion=, 42 bytes
malicious: collectEmailInfo CVE-2007-5659 detected
info: [2] no JavaScript
info: file: saved c41f10c79ccea7432987a9d7050604a3eb47 to (./temp/files/original_f21cc41f10c79ccea7432987a9d7050604a3eb47)
file: decoding_0c3be4288226f0bd341d8692d02a42652e9109e1: 78750 bytes
file: decoding_4074b66fea076c2f3fba4f4c05eb3f7329f4bde4: 42 bytes
file: original_f21cc41f10c79ccea7432987a9d7050604a3eb47: 13565 bytes
[/plain]
Now the same vulnerability is detected by both versions of the jsunpack tool. It's not redundant to also present the contents of the decoded files. The contents of the decoded file by the online version of the jsunpack tool are presented in the picture below:

The first decoded file 0c3be4288226f0bd341d8692d02a42652e9109e1 is shown below:

We didn't present the whole file, just the first part of it to be able to definitely say that the files are the same. If we look at the picture above, we can see that is starts with the "var BseFa", which is exactly the same as the first decoded file in the previous picture.
The jsunpack-n also decoded another file, which can be seen in the picture below:

This time the only content of the file is a comment about the Collab.collectEmailInfo vulnerability that was found in the malicious PDF document. I guess the decompression algorithm didn't continue the way we want (with other files being found, as with the online version of the tool), because we have a different version of pre.js JavaScript script that isn't as complete as the one used by the online version of the tool.
The decompressed files above represent each iteration in the deobfuscation process. The first file that starts with c41f is the actual downloaded PDF document. If there is only one decoded file, it means that Jsunpack didn't detect any decoded data and didn't decode anything; it just displays the found contents on the screen. But if there are multiple extracted files, we can be sure that the data within the document was encoded somehow. Usually the attackers employ encoding of the data to hide their content when sending exploits to the target machines. If the attacker is trying to hide something he will create two or more decodings, which can be successfully detected by Jsunpack.
The Jsunpack tool can detect up to five stages of decoding levels, which results in up to five files. The more levels there are, the more prominent is that the attacker is trying to hide something and that the document is indeed holding something malicious.
Conclusion
We've seen that Jsunpack can be a great help with decompressing the decoded PDF files and should be a mandatory tool when analyzing possibly malicious PDF documents.
Become a certified reverse engineer!
Sources


- Exam Pass Guarantee
- Live expert instruction
- Hands-on labs
- CREA exam voucher
In this series
- Analyzing malicious JavaScript
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
