Complete Tour of PE and ELF: Section Headers

In the previous part, we have discussed the ELF and Program Header. In this article, we will cover the remaining part i.e. section headers. We will also see what effect packers have on binaries headers.


FREE role-guided training plans
Below is the structure of Section Header

- Sh_name: Remember in ELF Header we talked about string table. sh_name is an offset into the string table which points to the name of the section. Section Name can be any long in ELF where in PE section name can be only 8 bytes. In ELF, it just has to be null terminated.
-
Sh_type: This field is used by the linker to store relevant information into. It has many subtypes. Following are the important ones:
- SHT_PROGBITS: This is used to catch all things which are not special or you can also say generic things.
- SHT_STRTAB: This is used to map to String Tables.
- SHT_DYNAMIC: This contains all the dynamic linkage information
- SHT_NOBITS: This contains data which take no space over disk but gets mapped into memory (Remember .bss ?)
- SHT_HASH: It contains the symbol table hash
- SHT_SYMTAB: It contains symbol table information used for debugging.
-
Sh_flags: This occupies following values:
- SHF_WRITE: 0x01;means the section is writable
- SHF_ALLOC: 0x04; this flag specifies whether or not this section will occupy memory during execution or not.
- SHF_EXECINSTR:0x02; means the section contains executable code and when mapped into memory should be marked as executable
- Sh_addr: This section states wherein the memory this section starts. A value of 0 indicates that this section does not reside in memory
- Sh_offset: This tells the file offset to the start of this data
- Sh_size: This tells the size of the section.
-
Sh_addralign: This shows the section alignment. This value should be a multiple of 2.
Below is the screenshot which displays section headers
- readelf –S hello
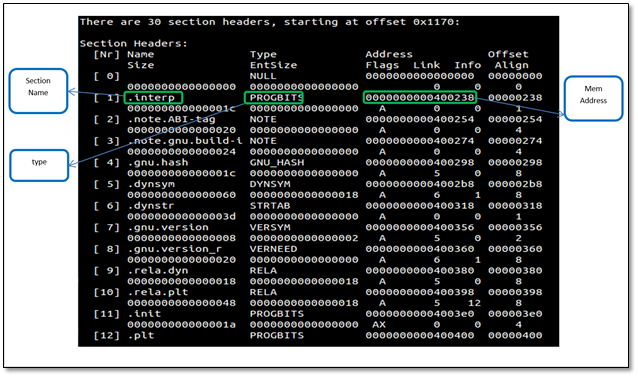
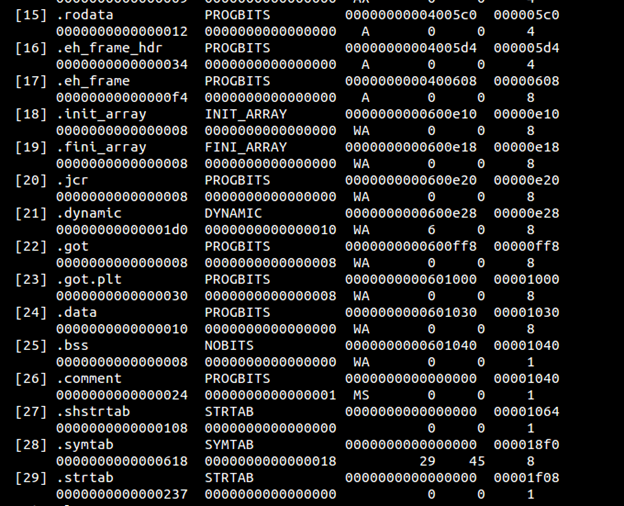
See how each section has been assigned a particular type, for example, .bss NOBITS type. Most of the sections map to what we saw in PE. .got is Global Offset Table and .plt is a procedure linkage table. To understand these fields we have to go back to the concept of relocations. Whenever an elf file references a function from a shared library, it does not get filled up until it is called in the code, i.e., at link time we can see that the in our object file hello.o , puts does not have a relocation information yet and is thus referenced as a type of R_X86_64_PC32 . It says in the final binary patch the address of puts at offset 0xa .

If we can disassemble this file, we can also see that at offset 0xa it is waiting for a 4-byte address to be filled in.
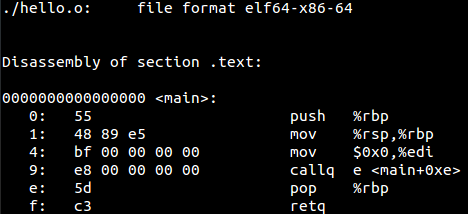
As we can see above that call to printf(puts) is done at PLT 0x400410 which jumps to GOT at 0x601018

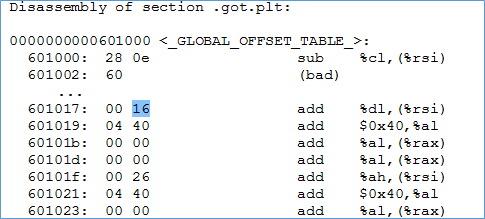
Examining the value at 601018 turns out to be next instruction i.e. pushq 0x0. Then the code makes a jump to PLT at 400400 which first pushed the value at 601008 (probably dynamic linker) and then call dynamic linker.

Whenever an external library function is referenced, then on first call the stub will be called which in turn will call dynamic linker with the address of the called function. The dynamic linker now knows that it has got the address of the function and must patch it up back in GOT. As we can see below now, the puts have to address to map to.
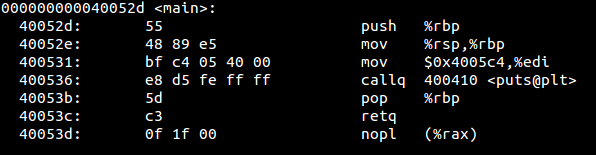
I think that we will be all for ELF section headers and thus the complete ELF structure.
Packers
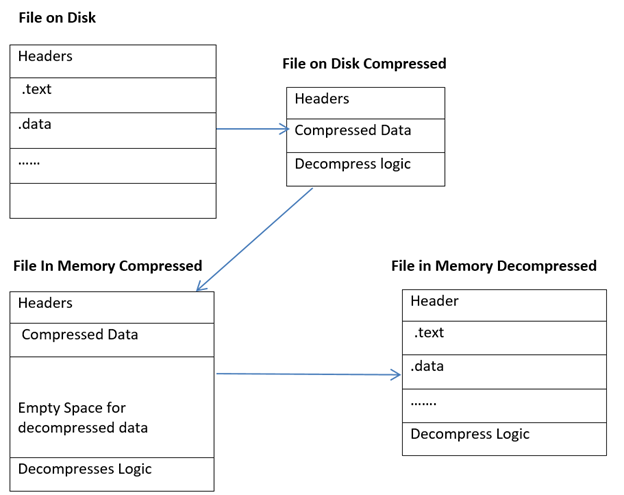
Packers were originally used to compress executables to increase disk space but these days packers are being used to obfuscate binaries. So once packer packs the file, it is the packer responsibility to decompress the binary in memory as would OS loader have done. It dons the role of OS loader at that point. To a binary it does not matter, and it gets decompressed and then being referenced in memory. So this means that all of our sections(.text, rdata etc.) will not be visible in the packed file and thus, no inference about the data in their can be made until the file gets decompressed in memory.
As we can see above is that packer compresses the file on disk and loads it into memory. While loading it into memory, it allocates a chunk for empty memory size which is for the data that will be decompressed. After this, the packer decompresses logic will jump back to AddressOf EntryPoint so that binary can run properly.
I am running UPX packer. (Important point to note with upx packer is that your file has to be at least 40 bytes large otherwise UPX will throw a NotCompressibleException . Compile the static version of the small file that will have all the code loaded into it already so it will be large). Below is the output of what changes has UPX made to the headers of ELF.
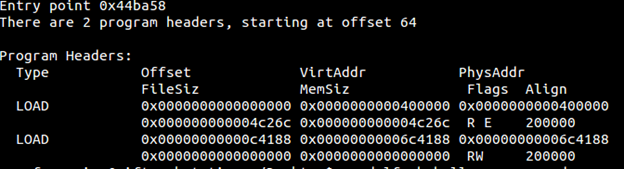
Note there are only two program headers and no section headers. This means it will load this compressed load segments in memory and then decompress them.
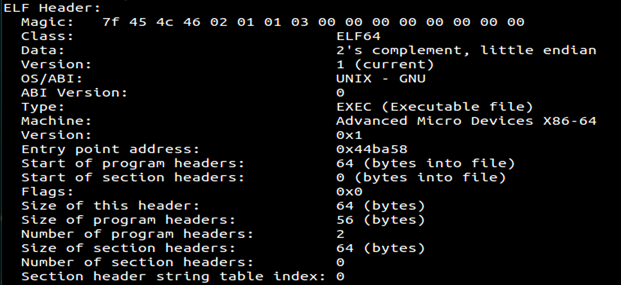
The Same thing can be seen with PE files.

What should you learn next?
So this brings us to the end of PE and ELF structures. Having a good understanding of these will help in performing malware analysis.


- 12 pre-built training plans
- Employer-requested skills
- Personalized, hands-on training
In this series
- Complete Tour of PE and ELF: Section Headers
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
