Machine Learning : Naïve Bayes Rule for Malware Detection and Classification


ABSTRACT: This paper presents statistics and machine learning principles as an exercise while analyzing malware. Conditional probability or Bayes' probability is what we will use to gain insight into the data gleaned from a sample set and how you might use it to make your own poor man's malware classifier.
Learn Cybersecurity Data Science
Notwithstanding the rather intuitive premise the use of Bayes' theorem has wide ranging applications from automatic music transcription, speech recognition and spam classifiers. We will first take an overview of what conditional probability is all about and thereafter we will build our own malware classifier for the Android platform as well as see the approach you might take to apply the same to mail spam identifiers.
HUMAN MODELLED
Bayes' Rule has revealed that the human mind also works in terms of probabilistic models. The mind can be modeled in terms of expectations which can be boiled down to numbers. Think of learning a new language and hearing it from a native– you would try to pick out a set of words from a preset list of learned words that are best suited to the context. That is Bayes rule in action if the mind can indeed be simplified to an equation. You are choosing the set of words in a specific sequence – for instance in French you are hearing– "Je suis tres bon." Translating to "I am very good." You would choose between Je /Vous (I/You), suis/etre (the verb "to be" in different declensions) and likewise. If you identified the word 'Je' followed by 'suis' you already guessed that the speaker is trying to say something about himself (or a similar context). After 'tres' anyone of the adjectives can be appended to denote what the speaker is trying to convey.
A second example would be music key transcription in music software. Here a most probable set of pitches are gathered in something we will call 'structures' that compile a set of most probable pitches played in a song in a particular key. The familiar major and minor scales have a preset pattern. So analyzing a large body of music would give us the statistical values of each note in each key being used in so many songs. These histogram numbers can then be converted to a probability models by simply counting the corpus of music containing the pitch out of the sample corpus. This would constitute the training data set. Thus given an input sequence from any song from a test corpus, the piecewise identified parts of the music – say 4 bars or any other optimized musical unit, can be immediately searched for the list of probability scores and the highest scores after multiplying each pitch probability would give us an indication of the key it most likely is in. Bayes Rule is very good in searching patterns using probability in statistical distributions, where the variables are dependent and can occur as a result of a previous variable. This makes it very attractive to prediction and classification purposes.
CONDITIONAL PROBABILITY
One of the better definitions of probability would be to represent it as a mathematical function where it takes a variable as an input for a corresponding output that would signify the probability or the measure of chance of that variable having the entered value. The output has to be between 0 and 1. The probability thus can be denoted as 0. Distribution would simply be the set of individual probabilities for all values of the input variable.
The familiar example of the probability of a die rolling to a particular numeric is a good illustration of probability in action. For each side of the cube a number is assigned and thus total number of variations for a single die amount to 6. We can denote the set of individual numbers as the sample set.
S1 = {1,2,3,4,5,6}
For each throw we are interested in the number on the top facing cube. There can be only one such number within the sample space. Thus individual probabilities of each number in the sample set would be any one number within the sample set for each throw. Given that the die is balanced the individual probability is equal for all numbers. Thus the probability of 1,P(1) = 1/6, P(2)=1/6 and so on. Reads more like occurrence of number 1 out of 6 numbers; occurrence of number 2 out of 6 numbers; there is only one of each number in the set, making the numbers unique, hence the numerator will be one in each case.This combined set of individual probabilities would be the distribution. In this case the summation of the fractions thus obtained must equal to one (1/6 X 6 equals 1).
In a second scenario, say we had two dice A and B, and we want to know the probability of getting a 2 in one die given we already have a 1 on another die. Here the variables are completely independent. This would be represented in a Venn diagram as the intersection of the two probabilities A and B. In this case the individual probabilities are simply multiplied.
Getting to the more relevant scenario of interdependent variables takes us to Bayes' rule. In the simplest terms, when rephrasing the definition to malware classification, it is the probability of a CLASS given a BINARY. Represented by P(CLASS|BINARY). CLASS could denote the two main types of MALWARE and BENIGN. Where the | symbol translates to 'given'. It can be shown that –
P(CLASS|BINARY) is proportional to P(BINARY|CLASS)*P(CLASS)
Here the P(CLASS) would be the prior probability and the P(CLASS|BINARY) is the posterior probability. These parameters are very important especially the prior value as that gives a statistical bias towards the resulting CLASS out of the entire sample set.
The proofs are rather logical and I encourage you to go as deep as you would like. Here the conditional quality is expressed in the fact that we want to know the type of the given binary and try to confirm if it is malware or a benign.
Thus taking the types in our CLASS and calculating the probability for each of them we get:
P(BENIGN|BINARY) = P(BINARY|BENIGN) P(BENIGN)
P(MALWARE|BINARY) = P(BINARY|MALWARE) P(MALWARE)
Since the values are proportional, we just need to compare the two values and assign the greater value as the final result.
That's all to conditional probability for our purposes. Other techniques like regression and ranking will be covered in the coming articles. Further interesting topics of Hidden Markov models, which also deals with probabilities and their predictive usage, will need this as a precursor.
IMPLEMENTATION
To classify a set of Android binaries, the approach I have taken for the preliminary classification involves use of publicly available research data sets which are complete enough to replicate in my lab. Also, statistically relevant research data will be the most useful for our purposes. The most useful for first reference is the Android Genome Project dataset of 1260 malwares. One of the graphs denotes the histogram of permissions found in 1260 malwares and 1260 benign Android applications. This would be very good test set for the first phase of Naïve Bayes Classification. We call it naïve because we make an assumption of the prior probabilities and tune the value to get the right classification. The top 20 permissions are what have plotted with the count of the number of malwares within the set of 1260 malwares that have this permission. This is exactly the data filtering that is already done for us. Admittedly re-running an Android permission extracting code on my own Android malware collection and then on a set of Android legitimate apps, I got a 99% accurate number both times. The code extracts the complete permissions and stores it in a list and after the sample set is completed it is sorted in descending order to give us the top 20 permissions on each sample set.
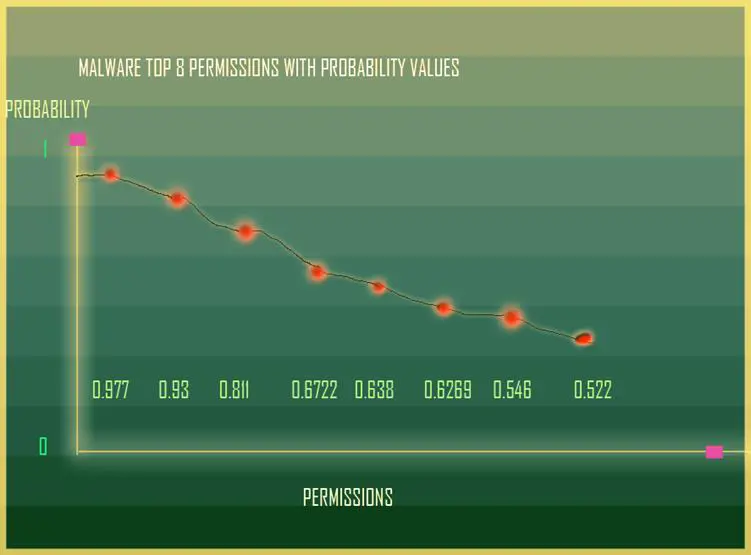
Relating to Bayes Rule, the other thing to introduce regarding the calculations is to multiply each of the probabilities within a variable set. Applying that to our obtained permissions histogram, we simply make a list including each permission by taking the fraction of the (number of malware having that permission)/total number of malwares in set. Repeat and rinse for the benign collection.
What we get are 2 lists containing the probabilities of each of the top 20 permissions for malware and legitimate .apk files. The first step to getting the code right would be to write C# enumerators for each of the probability distributions. Each enum below inherits from int data type denoting all numeric values are of integer type. The declaration of enums takes the format –
enum {}
Enums are a way to give names to constants. Here each permission string is assigned an integer value. When the names are called they can be type-casted to int. Here the frequency of malwares for each permission in the respective sample sets are given in the format –
[plain]
PERMISSION_NAME = FREQUENCY (COUNT OF FILES IN THE SAMPLE SET)
public enum perm20 : int{
INTERNET = 1232,
READ_PHONE_STATE=1179,
ACCESS_NETWORK_STATE = 1023,
WRITE_EXTERNAL_STORAGE=847,
ACCESS_WIFI_STATE=804,
READ_SMS=790,
RECEIVE_BOOT_COMPLETED=688,
WRITE_SMS=658,
SEND_SMS=553,
RECEIVE_SMS=499,
VIBRATE=483,
ACCESS_COARSE_LOCATION=480,
READ_CONTACTS=457,
ACCESS_FINE_LOCATION=432,
WAKE_LOCK=425,
CALL_PHONE=424,
CHANGE_WIFI_STATE=398,
WRITE_CONTACTS=374,
WRITE_APN_SETTINGS=349,
RESTART_PACKAGES=333
}
public enum perm20Benign : int {
INTERNET=1122,
ACCESS_NETWORK_STATE=913,
WRITE_EXTERNAL_STORAGE=488,
READ_PHONE_STATE=433,
VIBRATE=287,
ACCESS_FINE_LOCATION=285,
ACCESS_COARSE_LOCATION=263,
WAKE_LOCK=218,
RECEIVE_BOOT_COMPLETED=137,
ACCESS_WIFI_STATE=134,
CALL_PHONE=114,
CAMERA=73,
READ_CONTACTS=71,
GET_TASKS=60,
GET_ACCOUNTS=54,
SET_WALLPAPER=49,
SEND_SMS=43,
WRITE_SETTINGS=39,
CHANGE_WIFI_STATE=34,
RESTART_PACKAGES=33
}
The actual calculations involve just multiplying the set of permissions in each Android file,calculating the Bayes probability for each permission set per malware, and repeating the same for the benign set.
CAVEAT: It's very important to divide the training set and the testing set to make sure that the testing is optimal and that the training is not over fitted. That is to say it only works with the training set and not real world data. Hence the tuning has to be done by bifurcating the sample set into training and testing data sets.This is must for any machine learning process whether they are neural nets or Bayes' classifiers.
The calculating functions look like this –
[plain]
public void setScore(List p) {
intmalIdx = 0; intgoodIdx = 0;
for each (perm20 mal in Enum.GetValues(typeof(perm20)))
{
foreach (string l in p ){
stringtmp = getUpper(l);
if (tmp.Contains(mal.ToString()))
{
malScore *= (float.Parse(((int)mal).ToString())/ 1260);
//above does the probability multiplication
PermCount++;
mar[malIdx] = 1; //hit flagger for viz
}
} malIdx++;
}
foreach (perm20Benign good in Enum.GetValues(typeof(perm20Benign)))
{
foreach (string l in p)
{
if (getUpper(l).Contains(good.ToString()))
{
benignScore *= (float.Parse(((int)good).ToString()) / 1260);
ben[goodIdx] = 1;
}
} goodIdx++;
}
A utility function to get the upper case characters from the enum values:
[plain]
private string getUpper(string a) {
char[] c = a.ToCharArray();
StringBuilder s = new StringBuilder();
foreach (char f in c) {
if (Char.IsUpper(f) || f=='_') { s.Append(f); }
}
returns.ToString();
}
Noting other research data, I included the permissions count as well as a post analysis value to factor in to make a final decision.
[plain]
intPermCount = 0;
publicint COUNT {
get {return PermCount;}
}
NORMALIZATION: It might not be required at this stage, but range representation, or normalization,is done using various methods. The sigmoid representation is used to normalize positive values. In case negative values are needed or more specifically a bipolar representation is required then the hyperbolic function is used instead. In many cases its best to start with simply taking a reciprocal of the values for a particular range. This in effect normalizes the entire range within values from 0 to 1.
Sigmoid (X)= 1/(1+e^-X)
Hyperbolic(X) = (e^2X -1 )/(e^2X+1)
Reciprocal (X) = 1/X
I initialized the final score variables as floating point data types.
Representing probability ranges are best done with values from 0 to 1 and since the intermediate values are going to be very small after multiplying floating point numbers.
[plain]
floatmalScore=0.001f;
floatbenignScore=0.001f;
string verdict = String.Empty;
These properties below are used to return the values to another class.
[plain]
public string VERDICT { get { return verdict; } }
public double MALSCORE { get { return malScore; } }
public double GOODSCORE { get { return benignScore; } }
I also used two integer arrays to be used to initialize the permissions visualize for further visualization purposes later if required. They store the top 20 permissions as a hit flag set. 1 for every hit and 0 for empty places. Also their respective properties are initialized for later recall.
[plain]
int[] mar = new int[20];
int[] ben = new int[20];
publicint[] MALVIZ {
get { return mar; }
}
publicint[] BENVIZ {
get { return ben; }
}
All of the above code can be encapsulated in a C# class and kept ready for modular use. This class is named bayesClassifier.cs.
In another class where bulk of the extraction happens, an IO function writes the calculated values for each file in the training set to a file called stats.txtin the current directory. Remember to use half of each sample sets. Keep the other half for testing.IO() takes two values calculated from the bayesClassifier.cs. Though the IO() function takes two strings, I currently feed the file size and permissions count along with the malware Bayes probability and the benign probability strings.
[plain]
bayesClassifier.cspS = new bayesClassifier.cs(); //instance of the permissionScore class
pS.setScore(_MANSET[idx]._PERMSET); // setScore() called passing extracted permissions string list.
IO(pS.COUNT.ToString() + "," + _FILEPROPS[0].FILESIZE.Substring(0, _FILEPROPS[0].FILESIZE.Length-6) + "," + pS.MALSCORE.ToString(), pS.GOODSCORE.ToString());
private void IO(string malScore, string benignScore)
{
using (FileStreamfs = new FileStream(Environment.CurrentDirectory + "stats.txt", FileMode.Append, FileAccess.Write))
{
using (StreamWritersw = new StreamWriter(fs))
{
sw.WriteLine(malScore + "," + benignScore);
}
}
}
Running half the sample set of malware and benign samples give us a csv set of data that can be investigated for patterns and scores to further tune the classification for the test set.
A thing that should remind you of the 'Naïve' part of this exercise is the following values set in the bayesClassifier.cs code after the probability multiplication is done.
benignScore *= 0.80f;
malScore *= 0.20f;
These are the prior probabilities for each of the sample sets that are statistically assumed based on the overall space of legitimate vs. malware apps. This value might need to be tuned before it delivers the right classification. A value of 0.80 for benign apps indicates that the assumption taken that about 80% of applications in the Android app space are legitimate applications and that malware constitute about 20% of the total number.
An excerpt of 3 rows from the final stats.txt runs on 500 malware samples –
You could immediately see that the malware probability values are greater than the calculated benign probability for the same malware sample. Rerunning this on the benign set also gives interesting and expected data sets. More on that and further tuning of the data set parameters in the next article.
CONCLUSION:
Machine learning is not at all intimidating if you approach it in practical terms. Having its roots in statistics and probability,the application of Bayes theorem has caught on like wild fire, and for a reason – it works pretty well once the data is curated properly. You have learned about the fundamentals of Naïve Bayes Theorem and gotten an overview of conditional probability.
You have also gained a step by step understanding of implementation of Bayes Rule to Android malware detection and classification as a preliminary step towards a working classification engine.
Learn Cybersecurity Data Science
In the next part I will discuss other machine learning approaches towards building an Android malware analyzer while making use of the data gleaned from this exercise. Spam mail detection is another excellent example that will be discussed in the next article as a continuation to this series of machine learning fundamentals for malware analysis and security research.

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
