Big Data Discrimination

Introduced in 1997, the term "Big Data" has grown in popularity in the past years.

Learn Cybersecurity Data Science
Credit: IBM-Big-Data-Definitions by DigitalRalph / (CC BY 2.0)
53% of HR departments include Big Data in their strategic decisions; 71% use it to facilitate the sourcing, recruitment or selection of candidates; and 61% employ it to manage talent and performance.
Credit: The Operating Model for A Socially Engaged Business by Dion Hinchcliffe
The Wall Street Journal described the professional relationships between insurers, employee wellness firms and employers established to mine and make sense out of data on what kinds of drugs workers buy, how they shop, and even whether they vote, to determine health status and needs, as well as recommend treatments. Employees are being encouraged to wear smart fitness trackers by employers justifying this action by explaining how Big Data analysis will promote employee wellness and bring down health insurance costs at the same time.
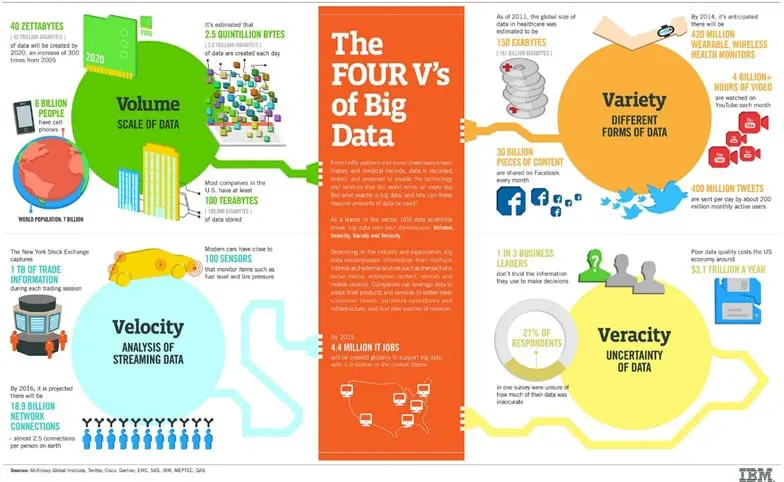
Credit: The 4 Vs of Big Data by Olivier Carré-Delisle / (CC BY-ND 2.0)
IBM's Personality Insights is a good illustration of a service that has the capability to build a detailed profile of a person, whose coverage will move beyond location information to include online and offline habits, political believes, professional and personal interests, etc. How do industry representatives manage to justify the use of Big Data? They simply claim that it improves users' 'online experiences'.
Nevertheless, every coin has two sides. In its report "Big Data: A Tool for Inclusion or Exclusion?," the Federal Trade Commission /FTC/ scrutinizes the pros and cons of relying on Big Data for marketing purposes, which is a practice that is growing in popularity. Consumers generally realize that their personal data is being collected because they are being monitored at every step of their purchasing process. They accept such an invasion of their privacy, seeing it as a payout for free services tailored to their particular needs and interests. Yet a 2016 report issued by the Obama administration gave a warning of "the potential of encoding discrimination in automated decisions."
In addition, "[a] commonly overlooked issue in Big Data systems is that they can incorporate and even reinforce discriminatory stereotypes
to the detriment of both users and the effectiveness of the system itself," states Saul Dorfman, a data scientist at ByteCubed.
Algorithms: The New Scales of Justice
Data mining is a computing process that uncovers indiscernible-to-naked-eye patterns in sizeable data sets by using methods from database systems, statistics, machine learning, and artificial intelligence. In other words, data mining is part of the Big Data.
Data mining algorithms have been used in recent times to improve network intrusion detection mechanisms to prevent cyber attacks, such as DDoS. An algorithm is a set of mathematical procedures coded for a particular purpose. Many vendors in the Big Data industry tout the algorithms as an "alchemical formula" excluding the human element during the process that will turn data into gold, thereby reducing the unlawful bias, especially in the early stages of recruiting candidates.

In a scientific paper, the authors propose different data mining techniques that may be able to weed out phishing attempts from all spam emails. They, however, allude to the fact that neither of the current methods at hand can provide 100% accuracy. That may lead to a situation where some non-threatening emails are excluded at the expense of others (that may, in fact, pose a real danger to the receiver).
"[A]dvocates of algorithmic techniques like data mining argue that they eliminate human biases from the decision-making process. However, an algorithm is only as good as the data it works with [,]" voices his opinion the researcher Solon Barocas in his 2014 report titled "Big Data's Disparate Impact." [D]ata mining can inherit the prejudices of prior decision-makers or reflect the widespread biases that persist in society at large."
The logic is simple – machine learning systems rely on algorithms created by human beings to process data originating from human beings; thus, the final product of this data processing would eventually carry the implicit human biases. In essence, imperfect inputs produce imperfect results. Discrimination can occur either intentionally or by mistake.
According to the FTC, companies should be careful with Big Data analytics in cases where information from particular populations is missing, or there are other similar omissions that may allow hidden biases to creep in.
The data mining through algorithms also tracks down the "digital footprints" on passive candidates – those who have not applied for a job or are not actively looking for new employment – as part of the growing and increasingly fierce competition for talent. In reality, some workforce groups have not as distinctive "digital footprint" as others do. The logical question is, then: How will the data mining process address this disparity? The Big Data algorithms may also not reflect on, or be able to measure precisely, an individual's ability to execute his job duties.
Ambiguous characteristics such as social media usage and ZIP codes may be present in predictive analytics to determine a consumer's creditworthiness. Regular human oversight of data accuracy and algorithm bias is an advisable measure.
"For example, one company determined that employees who live closer to their jobs stay at these jobs longer than those who live farther away. However, another company decided to exclude this factor from its hiring algorithm because of concerns about racial discrimination, particularly since different neighborhoods can have different racial compositions." /Source: FTC Warns Against Use and Misuse of Big Data Analytics/
Root Insurance is an insurance company that claims that most companies in the sector calculate insurance premiums by rating variables such as education level or occupation. This company, on the other hand, prefers to disregard such factors, which they deemed 'unfair,' and instead choose to focus on more practical factors, i.e. 'variables within an individual's control,' namely driving habits. That would mean better drivers would be rewarded with better prices.
Another good illustration of how algorithms may actually facilitate practices that would generate concern is what Dr. Kelly Trindel, Chief Analyst in EEOC's Office of Information, Research, and Planning, shared before the U.S. Equal Employment Opportunity Commission:
"If the training phase for a big data algorithm happened to identify a greater pattern of absences for a group of people with disabilities, it might cluster the relevant people together to create a 'high absenteeism risk' profile. The profile need not be tagged as 'disability'-rather it might appear to be based on some group of financial, consumer, or social media behaviors."
Additionally, the algorithms may be designed to replicate the workforce's demographics existing in the company.

Credit: The Future of Big Data Requires a Human Algorithm by Brian Solis / (CC BY-ND 2.0)
Real Life Examples of What May Constitute Big Data Discrimination
In the spring of 2017, Palantir Technologies had to pay $1.7 million in back pay, as well as other compensation, to Asian job applicants whose applications were rejected. The U.S. Department of Labor brought a hiring discrimination lawsuit against the Silicon Valley software company in September 2016.
After a compliance review, the Office of Federal Contract Compliance Programs determined that Palantir allegedly used a hiring process that "routinely eliminated" qualified Asian applicants during the phases of resume screening and telephone interviews, and instead hired predominantly people from its discriminatory referral systems. Under these circumstances, it is not difficult to imagine this scenario in a hiring process driven by Big Data analytics.
Discrimination as part of the standard decision-making is now part of Big Data decision-making.
Google Flu Trends, a machine-learning algorithm designed to predict cases of flu based on Google search terms, demonstrated some limitations of Big Data analytics. At first, the algorithm seemed to produce accurate predictions, showing where strains of flu are more prevalent, but it deteriorated over time since it started to generate highly inaccurate results.
A case often cited in connection with Big Data discrimination is associated with an extensive research conducted by Latanya Sweeny, Professor of Government, and Technology in Residence at Harvard University. She noticed that when one looks up on Google for certain kinds of names associated with a given race, black-sounding names are up to 25 % more likely to be served with an arrest-related ad than white-sounding names. The California-based company has had a poor track record of similar glitches, such as confusing gorillas with people and dogs with horses.

Credit: Predictive search on Google, Bing and Yahoo for bicycle related terms by Richard Masoner / Cyclelicious / (CC BY-SA 2.0) / Modified
The last example comes from the augmented reality world of the popular game Pokémon GO. Apparently, the scarcity of Pokemons in African American neighborhoods in comparison to other neighborhoods may be interpreted as a discriminatory act of sorts rooted in a technology-related prejudice.
U.S. Anti-discrimination Laws and Big Data
Jenny R. Yang, the Chair of the Equal Opportunity Employment Commission (EEOC), outlines some of the pros and cons with regard to the technology that is the main subject of this writing:
"Big Data has the potential to drive innovations that reduce bias in employment decisions and help employers make better decisions in hiring, performance evaluations, and promotions [.] At the same time, it is critical that these tools are designed to promote fairness and opportunity, so that reliance on these expanding sources of data does not create new barriers to opportunity."
A major problem seems to be, however, that the current legal environment is founded on rules and regulations created in an analog reality and they rarely come with instructions on how to adjust them to the world of Big Data.
Below you can find U.S. laws that may apply to Big Data businesses:
The Fair Credit Reporting Act – the FCRA covers all instances of collection and selling of consumer information concerning employment, credit, insurance, or other benefits. Consumer reporting agencies are subject to the FCRA. Under the law in question, these agencies must ensure that their reports are accurate and they have a procedure in place that will allow consumers to correct mistakes in their own data records.
An example of a violation of the FCRA would be a person not receiving marketing for a prime rate credit card due to non-traditional analytic predictors (e.g., social media use, relationship status, or zip code).
Equal Opportunity Laws – this term is a collective noun that encompasses numerous laws, which are enacted to prohibit discrimination on the grounds of race, religion, age, gender, marital status, etc. Some of these laws are the Equal Credit Opportunity Act, the Americans with Disabilities Act, the Age Discrimination in Employment Act, the Fair Housing Act, the Genetic Information Nondiscrimination Act, and Title VII of the Civil Rights Act of 1964.
In the context of Big Data, that would mean, for example, that a company's advertisements should not exclude certain groups of people based on characteristics protected under this set of laws.
Section 5 of the FTC Act authorizes the agency to take necessary measures to prevent unfair or deceptive acts or practices and impose fines on entities that commit such unfair or deceptive acts or practices. Under Section 5, the FTC will charge companies that fail to disclose material information to consumers, such as the possibility for algorithm-based bias during the processing of their personal information.
The FTC guidance points out that Big Data companies must not be selling "big data analytics products to customers if they know or have reason to know that those customers will use the products for fraudulent purposes." In the Choice Point case, a company "sold the personal information of more than 163,00 consumers to identity thieves posing as legitimate subscribers while allegedly ignorer "obvious red flags."""
If someone brings a discrimination case against an organization, he has to show evidence of disparate impact. Pursuant to the definition in the FTC report, disparate impact occurs in events when practices and/or policies of an organization have a "disproportionate adverse effect or impact on a protected class, unless those practices or policies a legitimate business need that cannot reasonably be achieved by means that are less disparate in their impact."

Credit: Discrimination by Nick Youngson / CC BY-SA 3.0
Best Practices to Root out Big Data Discrimination
There are some useful Big Data practices that may help an organization avoid discrimination and disparate effect:
- A thorough representative data set – some groups do not share much information, others have no access to technology or social media. That does not mean that they do not have purchasing power, for instance, and these people should be included in the data analysis as well.
- Take into consideration hidden biases embedded in your data model – the human component to data analysis is a conditio sine qua non, since almost all forms of data collection possess hidden biases, and they need to be tracked down and eliminated manually.
- Perform audits of data predictions on a regular basis – test Big Data predictions because even though accurate most of the time, they are still imperfect.
Transparency is perhaps the key ingredient to tackle Big Data discrimination, privacy, and security issues. Users should know, at the very least, what information is being gathered on them, for what kind of purposes, who has access to it, and what kinds of security controls companies have in place.
Also, strict adherence to the principles of fairness and ethics on Big Data analytics will only strengthen your reputation as a brand.
Closing Statement
The director of Center for Business Analytics at New York University's Stern School of Business, Anindya Ghose, is a huge proponent of Big Data analytics. Let's conclude the article with her words just to offer a stark contrast with the rest of it:
"In my academic research and industry consulting, I have seen tremendous benefits accruing to firms, organizations, and consumers alike from the use of data-driven decision-making, data science, and business analytics [.] To be perfectly honest, I do not at all understand these big-data cynics who engage in fear mongering about the implications of data analytics [.] Here is my message to the cynics and those who keep cautioning us: 'Deal with it, big data analytics is here to stay forever'."
***
"So let it be written. So let it be done."
***

Reference List
Basu, M. (2016). US report warns on big data discrimination. Available at https://govinsider.asia/security/us-report-warns-on-big-data-discrimination/ (01/06/2017)
Brennan, M. (2015). Can computers be racist? Big data, inequality, and discrimination. Available at https://www.fordfoundation.org/ideas/equals-change-blog/posts/can-computers-be-racist-big-data-inequality-and-discrimination/ (01/06/2017)
Carlson, C. (2016). FTC: Analyzing big data creates discrimination risk. Available at http://searchcompliance.techtarget.com/feature/FTC-Analyzing-big-data-creates-discrimination-risk-for-companies (01/06/2017)
Crauet, J. (2016). How to Avoid Discrimination in Automated Decisions: The challenges of humanizing big data. Available at http://bytecubed.com/how-to-avoid-discrimination-in-automated-decisions-the-challenges-of-humanizing-big-data/ (01/06/2017)
Cunningham, M. (2016). DATA DISCRIMINATION: THE DARK SIDE OF BIG DATA. Available at http://www.madmarketer.com/topics/digital/articles/419740-data-discrimination-dark-side-big-data.htm (01/06/2017)
Dickey, M. (2016). U.S. Department of Labor sues Palantir for racial discrimination. Available at https://techcrunch.com/2016/09/26/u-s-department-of-labor-sues-palantir-for-racial-discrimination/ (01/06/2017)
Fienberg, H. (2016). FTC Warns Against Use and Misuse of Big Data Analytics. Available at http://www.insightsassociation.org/article/ftc-warns-against-use-and-misuse-big-data-analytics (01/06/2017)
Frankel, S. (2016). Don't make this big mistake in big data boom. Available at http://www.cnbc.com/2016/03/15/dont-make-this-big-mistake-in-big-data-boom.html (01/06/2017)
Guynn,J. (2017). Palantir settles Asian hiring discrimination lawsuit. Available at https://www.usatoday.com/story/tech/news/2017/04/25/palantir-settles-asian-hiring-discrimination-lawsuit/100900496/ (01/06/2017)
Hale, Z. (2017). Technical Difficulties: A Primer on Big Data and Employment Discrimination. Available at http://ualr.edu/socialchange/2017/03/15/1231/ (01/06/2017)
Jon, C. (2016). How Apple Plans to Protect Your Privacy with Big Data. Available at https://dzone.com/articles/how-apple-plans-to-protect-your-privacy-with-big-d (01/06/2017)
Lin, G. (2016). Big Data: The Rise of Talent Analytics is a Cause for Concern. Available at http://www.employmentlawblog.info/2016/12/big-data-the-rise-of-talent-analytics-is-a-cause-for-concern.shtml (01/06/2017)
Mac, R. (2017). Palantir Pays $1.6 Million To Settle Hiring Discrimination Lawsuit With Department Of Labor. Available at https://www.forbes.com/sites/mattdrange/2017/04/25/palantir-pays-1-6-million-to-settle-hiring-discrimination-lawsuit-with-department-of-labor/ (01/06/2017)
McGowan, K. (2016). When Is Big Data Bad Data? When It Causes Bias. Available at https://www.bna.com/big-data-bad-n73014445584 (01/06/2017)
McKelvey, C. (2017) Got (algo)rithm? Show us your moves. Available at http://www.dataiq.co.uk/article/got-algorithm-show-us-your-moves (01/06/2017)
Merler S. (2017). Big data and first-degree price discrimination. Available at http://bruegel.org/2017/02/big-data-and-first-degree-price-discrimination/ (01/06/2017)
Ryoo, J. (2016). Big data security problems threaten consumers' privacy. Available at https://theconversation.com/big-data-security-problems-threaten-consumers-privacy-54798 (01/06/2017)
Sigdyal, P. (2016). Critics allege big data can be discriminatory, but is it really bias? Available at http://www.cnbc.com/2016/05/07/critics-allege-big-data-can-be-discriminatory-but-is-it-really-bias.html (01/06/2017)
Timm, A. (2017). Big Data Can Solve Discrimination. Available at http://insurancethoughtleadership.com/big-data-can-solve-discrimination/ (01/06/2017)
Smith, M., Patil, DJ., Muñoz, C. (2016). Big Risks, Big Opportunities: the Intersection of Big Data and Civil Rights. Available at https://obamawhitehouse.archives.gov/blog/2016/05/04/big-risks-big-opportunities-intersection-big-data-and-civil-rights (01/06/2017)
U.S. Equal Employment Opportunity Commission (2016). Use of Big Data Has Implications for Equal Employment Opportunity, Panel Tells EEOC. Available at https://www.eeoc.gov/eeoc/newsroom/release/10-13-16.cfm (01/06/2017)
Learn Cybersecurity Data Science

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
