Data loss prevention (DLP) strategy guide

In this article, we'll learn about the concept of data loss prevention: why it is needed, what are the different types of DLP and its modes of operations, what is the planning and design strategy for DLP, what are the possible deployment scenarios, and what are workflow and best practices for DLP operations.
Overview
Every organization fears losing its critical, confidential, highly restricted or restricted data. Fear of losing data amplifies for an organization if their critical data is hosted outside their premises, say onto a cloud model. To address this fear or issue that organizations face, a security concept known as "Data Loss Prevention" has evolved, and it comes in product flavors in the market. The most famous among them are Symantec, McAfee, Web-sense, etc. Each DLP product is designed to detect and prevent data from being leaked. These products are applied to prevent all channels through which data can be leaked.
Learn Incident Response
Data is classified in the category of in-store, in-use and in-transit. We will lean about these classifications later in this article. Before starting the article, we have to keep in mind that the information is leaking from within the organization.
Types of data to protect
First of all we need to understand what type of data is needed to be protected. In DLP, data is classified in three categories:
- Data in motion: Data that needs to be protected when in transit i.e. data on the wire. This includes channels like HTTP/S, FTP, IM, P2P, SMTP.
- Data in use: Data that resides on the end user workstation and needs to be protected from being leaked through removable media devices like USB, DVD, CD's etc. will fall under this category.
- Data at rest: Data that resides on file servers and DBs and needs to be monitored from being getting leaked will fall under this category.
DLP strategy
DLP products come with inbuilt policies that are already compliant with compliance standards like PCI, HIPPA, SOX, etc. Organizations just need to tune these policies with their organizational footprint. But the most important thing in DLP strategy is to identify the data to protect, because if an organization simply puts DLP across the whole organization, then a large number of false positives will result. The below section covers the data classification exercise.
Identify sensitive data
The first thing every organization should do is to identify all the confidential, restricted, and highly restricted data across the whole organization and across the three channels, i.e. for data in-transit, in-store and in-use. DLP products work with signatures to identify any restricted data when it is crossing boundaries. To identify the critical data and develop its signatures, there is a term in DLP products known as fingerprinting. Data is stored in various forms at various locations in an organization and it requires identifying and fingerprinting. Various products comes with a discovery engine which crawl all the data, index it and made it accessible though an intuitive interface which allows quick searching on data to find its sensitivity and ownership details.
Defining policies
Once the sensitive data is discovered, an organization should build policies to protect the sensitive data. Every policy must consist of some rules, such as to protect credit card numbers, PII, and social security numbers. If there is a requirement for an organization to protect sensitive information and the DLP product does not support it out of the box, then organizations should create rules using regular expressions (regex). It should be noted that DLP policies at this stage should only be defined and not applied.
Determining information flow
It is very important for an organization to identify their business information flow. An organization should prepare a questionnaire to identify and extract all the useful information. A sample questionnaire is provided below:
- What should be the source and destination of the identified data?
- What are all the egress points present in the network?
- What processes are in place to govern the informational flow?
Identifying business owners of data
Identification of business owners of data is also an important step in the planning strategy of DLP, so a list should be prepared of whom to send the notifications to in case any sensitive data is lost.
Deployment scenarios
As discussed earlier, sensitive data falls under three categories, i.e. data in motion, data at rest and data in use. After identifying the sensitive data and defining policies, the stage is then set up for the deployment of the DLP product. The below section covers the DLP deployment scenario of all three types:
- Data in motion: Data that needs to be protected when in transit, i.e. data on the wire. This includes channel like HTTP/S, FTP, IM, P2P, SMTP etc. The below diagram shows the common implementation of DLP.

As in the above diagram, it is clear that DLP is not put in inline mode but rather put on a span port. It is very important to not put DLP protector appliance or software directly inline with the traffic, as every organization should start with a minimal basis and if put inline, it would result in huge number of false positives. In addition, if the DLP appliance is put in place, there is always a fear of network outage if the inline device fails. So the best approach is to deploy the DLP appliance in a span port first, and then after the DLP strategy is mature, then put into inline mode.
To mitigate the second risk, there can be two options. First, deploy DLP in High Availability mode, and second, configure the inline DLP product in bypass mode, which will enable the traffic to bypass the inline DLP product in case the DLP product is down.
- Data in Use: Data that resides on the end user workstation and needs to be protected from being leaked through removable media devices like USB, DVD, CDs, etc. will fall under this category. In Data in Use, an agent is installed in every endpoint device like laptop, desktop, etc. which is loaded with policies and is managed by the centralized DLP management server. Agents can be distributed on the endpoints via pushing strategies like SMS, GPO, etc. Since a DLP agent on the endpoint needs to interact with the centralized DLP management server in order to report incidents and get refreshed policies, the communication port must be added as an exception in the local firewall list.
- Data in Store: Data that resides on file servers and DBs and needs to be monitored from being getting leaked will fall under this category. All the data that resides in storage servers or devices are crawled using a DLP crawling agent. After crawling, data is fingerprinted to see any unstructured data is present or not.
DLP operations
Deployment of security components is of no use if they cannot be monitored, and a DLP product is no exception. Below is an overview of what a DLP operation of an organization can be. First of all, the DLP product needs to be created with the right set of policies on the identified data among data at rest, in motion or in transit categories. I have tried to split the DLP operations into three phases, namely: triaging phase, reporting and escalation phase, and tuning phase. Let's understand these phases in detail.
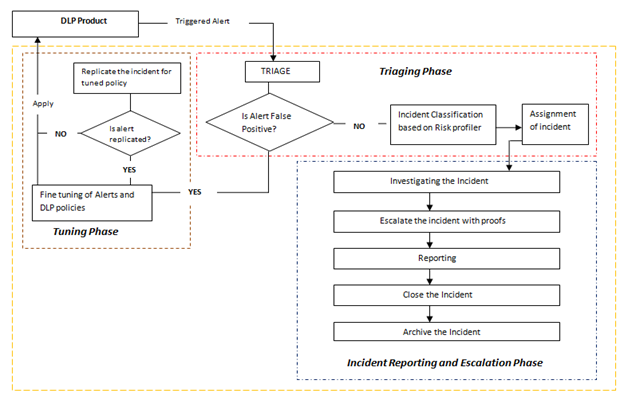
- Triaging phase: In this phase, the security operation's team will monitor the alert fired or triggered by the policies set up in the DLP product. As mentioned earlier, DLP first should be put in observation mode to see and remove all the false positives. So when the security team receives the alert, the team will triage that event against various conditions like what type of data has been leaked, who has leaked it, through which channel it got leaked, any policy mis-configuration, etc. After performing this triaging, the team will declare the alert as an incident and start the incident classification phase where the team will process the incident with a risk profile. A risk profile is a text-based sheet which includes important information about the incident like type of policy, data type, channel type, severity type (low, medium, high), etc. After processing and updating the risk profile, the security team will assign the incident to the respective team.
- Incident Reporting and Escalation phase: In this phase, the security team will assign the incident to the respective team. First, the security team will consult with the respective team to check whether the loss is a business acceptable risk or not. This can be due to reasons like change in policies at the backend, etc. If yes, the incident will be considered a false positive and moved to the tuning phase. If not, then the security team will escalate the incident along with proofs to the respective team. After escalating, security team will prepare the report as a part of monthly deliverable or for audit, and after this, the security team will close the incident and archive the incident. Archiving is important as some compliance requires it during a forensic investigation.
- Tuning phase: In this phase, all the incidents which are considered to be false positive are passed here. The security team's responsibility is to fine tune the policies as a result of some mis-configurations earlier or due to some business change and apply the changes to the DLP product as a draft version. To check whether the applied changes are fine, the incident is replicated and then checked whether the alert is generated or not. If not, then the changes are made final and applied, but if yes then fine tuning is required in the policies which are set up in the DLP product.
It should be noted that in DLP, there is no incident resolution phase, since any reported incident is a data loss (if it is not a false positive) and is thus escalated and then corresponding action is taken.
Best practices for a successful DLP implementation
Below are some of the best practices that should be adopted in order to have a successful pre and post DLP deployment.
- Before choosing a DLP product, organizations should identify the business need for DLP.
- Organizations should identify sensitive data prior to DLP deployment.
- While choosing a DLP product, organizations should check whether the DLP product supports the data formats in which data is stored in their environment.
- After choosing a DLP product, DLP implementation should start with a minimal base to handle false positives and the base should be increasing with more identification of critical or sensitive data.
- DLP operations should be effective in triaging to eliminate false positives and fine tuning of DLP policies.
- A RACI matrix should be setup to draw out the responsibilities of DLP policies, implementation etc.
- A regular updating of risk profiles and a thorough documentation of the DLP incidents.
Conclusion
DLP is a very good defensive and preventive technology that if implemented correctly, will surely prove to be a boon for organizations in respect to protecting their own data or their client's data.
Learn Incident Response
Sources

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
