Snort Rule Writing for the IT Professional: Part 3

Welcome back to my continuing series of articles on Snort rule writing.
My first couple of installments in this series addressed some very simple rules in order to lay down a conceptual framework for the development of more complex rules. See Part 1 and Part 2.
Learn Network Security Fundamentals
In this article, we will examine a slightly more complex rule that will elaborate on some of the key features in the options section of the rule, most particularly those that address inspection of the payload.
Payload inspection can be very CPU-intensive, but at the same time, payload inspection has become necessary as attacks have become increasingly sophisticated. Snort has built into its rule-writing language a number of keywords/tools that can be used to inspect the payload and do it rather efficiently. We will looking at a rule from the Snort rule set that addresses an attempted "sa" brute force login attempt in MS SQL Server to illustrate some of these features in the Snort rule language.
Our Example Rule:

We should already be familiar with the header of this rule. The action is alert, the protocol is tcp, the source IP is a variable defined in snort.conf as $EXTERNAL_NET, the source port is any, the direction is -> toward our network, the destination IP is a variable defined in snort.conf as $SQL_SERVERS and the destination port is SQL Server's default port 1433. The message sent to the Snort admin is "SQL SA brute force login attempt" and the flow is to the server and established, but now we address some new fields and concepts in Snort rules when we come to the content keyword.

As we saw earlier in the second installment in my series, the content keyword is designed to examine the packet payload for telltale signs of malicious activity. The content keyword requires that the material we are looking for in the payload be enclosed in double quotation marks. As we can see in this rule, we have content followed by |02| enclosed in double quotes. Whenever we are looking for content in the payload in a hexadecimal format as we are here, it must be between pipes (|). This portion of the rule is then looking for the hexadecimal 0x02 in the payload. This payload represents a well-known vulnerability in SQL Server 2000 whereby it will respond with critical system information when sent a payload of 0x02.
Immediately after that content couplet, we see a new keyword: depth. Depth indicates how many bytes into the packet the rule should count to find the content we are looking for. In this case, we are telling the Snort rule to look in the very first byte for this content. Putting such a limitation on the rule not only limits its false positives where such a character might appear somewhere else in the packet and not be malicious, but also makes it more efficient as the detection engine need only look in one place for the content and not the entire packet which can eat up significantly more CPU cycles.
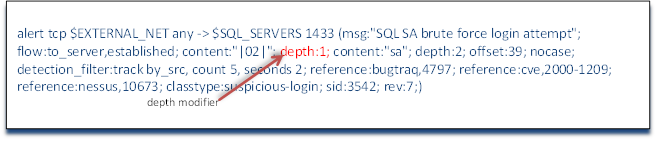
Next, we see that the rule has another content couplet. Snort allows for multiple content searches. It's worth noting here again, that Snort operates like a simple logic engine. All conditions before a new condition must evaluate to true before it will even consider this next condition. If any of the conditions in our header or preceding option fields evaluate to false, the rest of the rule is not read or evaluated. So, in our rule here, Snort must have found "|2|" in the first byte in order to come to this new condition. If it hadn't, the rule would exit and go to the next rule. This raises an important point in writing rules for best performance. Obviously, rules options that are very restrictive should always precede rules that are less restrictive. In other words, we put the conditions that are most likely to evaluate to false FIRST in our list of option conditions. In this way, the Snort detection has to expend fewer CPU cycles in evaluating the rule because it doesn't have to go as deep into the rule or as deep into the packet to evaluate the truth of the overall rule. The rule will work the other way around (most likely to evaluate to true), but will take more time and computing power to evaluate it. It's critical to consider the efficiency of rules because each rule has to be evaluated against every packet and if the network is under heavy load, we don't want to miss any packets.
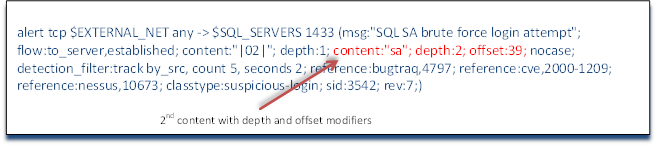
This next couplet, content: “sa” and the modifiers that follow it will demonstrate some powerful features of Snort rule writing. First, this couplet is looking for payload content that includes the two characters “sa”. As we are examining only SQL Server traffic (port 1433) this would indicate that someone is trying to login to the system administrator (sa) of SQL Server (remember that MS SQL Server 2000 had a default configuration with the sa account with no password). Next, this content matcher is modified then with the keyword depth and the number 2. This is then followed by the keyword offset and the number 39. The combination of the depth keyword with the offset keyword as used here would be interpreted to mean “Look for sa in the payload starting in the 39th byte and look within the next two bytes”. Although it might be much easier on us to write the rule without these restrictions, it is much easier on the Snort detection engine the more restrictive and specific we can be and still catch the malicious payload.

All content matching in Snort rules is case sensitive. If we want to search for content without regard to case, we can add the keyword nocase. As you see in our rule example here that we have added the word nocase which tells Snort to look for our content independent of case. This means that it would evaluate true for sa, SA, Sa, and sA.

After the content matching section and its modifiers, we see some new keywords "detection_filter: by_src". Detection filters set up a threshold whereby a rule's conditions are not triggered until they hit the defined threshold level. So, in our case here, we are looking to detect when someone tries to brute force the sa account in SQL Server. We probably don't want to be alerted every time someone tries sa against our SQL Server it as it would likely generate too many alerts to track effectively and it would also alert us to legitimate sa traffic as well. Instead, we can establish a minimum threshold whereby we would be alerted to this type of traffic. A single sa to the SQL Server is probably not malicious, so we should ignore it, but if we get multiple packets in a short time span, we can reasonably conclude that it is malicious and we need to be alerted. This minimum threshold can be further refined by selecting whether this threshold should be applied to the source IP address or the destination IP address. Here we are looking to apply our minimum threshold to the source IP address by modifying the detection_filter keyword with track by_src forming the couplet of detection_filter:track by_src (we can also track by_dst). We are now tracking brute force sa attempts on our SQL Server by source IP. Lastly, we need to quantify the threshold level.
The threshold levels are defined by the number of matches within a period of time. The keywords are relatively intuitive so that the number of matches is defined by the keyword count and the time period is defined by the keyword seconds. In our example rule, we have defined the threshold count as 5 within 2 seconds. This means that if we see five attempted brute force sa logins on our SQL Server application server within 2 seconds, send an alert. Anything less than this threshold level will be ignored. A couple of important notes here about these threshold level detection filters: First, count can be abbreviated as c and seconds can be abbreviated as s, so this detection level could have been written as detection_filter: track by_src c 5 s2. It is recommended, and considered a best practice, to use the full words count and seconds as it makes debugging more intuitive and therefore, much easier. Second, note that these threshold level parameters appear as a couplet like nearly everything else in the option's section of a Snort rule, but this couplet does not have a colon between the first and second part (there is no colon between count and 5, for instance). Third, the detection_filter applies to the entire rule independent of where it appears in the rule. It can be placed anywhere in the options section and applies to the threshold level of triggering the entire rule alert.
Metadata
Everything in this rule up until this point provided conditions for the rule to trigger. Each couplet could be evaluated to either true or false. Now we come to the metadata. As we have seen from our simple rule in the second of my rule-writing installments, this can be very simple with the Snort Rule ID (SID) and the revision number (ver), but in this rule we provide significantly more information.
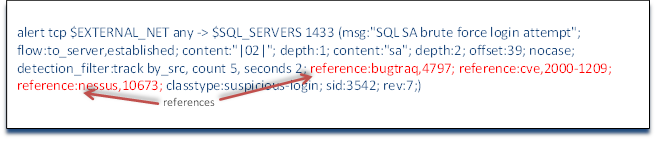
It is a generally-accepted best practice in writing a snort rule to provide a reference to the vulnerability or exploit that the rule is meant to detect. This provides the Snort administrator some background information should they find this rule triggered in their log or alerts. It would be of limited usefulness to an administrator to see this rule triggered, but not know what was triggering it without interpreting the structure and syntax of each rule.
In our example rule, we can see that the first reference is bugtraq (reference:bugtraq,4797). The syntax here is the keyword reference, the reference source (in this case buqtraq) and the reference number within the source, in this case 4797. In this way, if this rule were to be triggered and we didn't understand what it was developed to detect, we could simply search online to www.securityfocus.com website. There we could search their bugtraq database for 4797 and would see that this is a vulnerability first reported May 22, 2002 that SQL Server 2000 had a default setting on the sa account without a password. It provides us with a plethora of information on each vulnerability or exploit that can be useful in deciphering what just took place on your network. In the case of 4797, the description reads, in part;
It has been reported Microsoft MSDE and SQL Server 2000 Desktop Engine are configured by default with a null administrative password by default. Remote attackers may exploit this flaw to gain administrative access to the database if the password has not been manually changed.
Next, we see further references on cve and nessus. Note that the syntax in this section is the keyword reference, the colon, then the reference source, comma, and then numeric index of the exploit within that reference source.
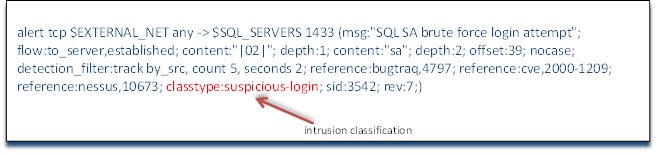
After the references section, we return to familiar ground. Here, we see the classification of the rule. As I pointed out in the second installment of my series, Snort has default classification for all rules and these classifications have default severity levels. In this case, as you might expect, it is classified as classtype:suspicious-login; From my Snort Rule Writing for the IT Professional Part #2, we can see that suspicious logins have a default severity level of medium and represents "an attempted login using a suspicious username was detected".

Lastly, this rule has Snort ID of 3542 and is on revision 7.
Learn Network Security Fundamentals
In my next installment in this series, we will look at such powerful features in Snort rules that enable us to detect malicious activity across multiple packets.

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
