Chapter 11 – Identity management and access controls

Access controls help us restrict whom and what accesses our information resources, and they possess four general functions: identity verification, authentication, authorization, and accountability. These functions work together to grant access to resources and constrain what a subject can do with them.
This chapter reviews each access control function, four approaches to access control/role management, and takes a brief look at the future of access controls.

What should you learn next?
Identity management
Identity management consists of one or more processes to verify the identity of a subject attempting to access an object. However, it does not provide 100 percent assurance of the subject's identity. Rather, it provides a level of probability of assurance. The level of probability depends on the identity verification processes in place and their general trustworthiness.
Identity defined
A good electronic identity is something that is verifiable and difficult to reproduce. It must also be easy to use. A difficult to use identity is an identity or a related service/application not used.
An example of an ineffective identity is an account ID and password combination. It is easy to use but also often easy to reproduce. Any single piece of information that is easily guessed or stolen cannot provide high enough identity probability (IP). I will not go into the ubiquitous reasons passwords are weak forms of identity management. This is easily discovered with a quick Google search. For our purposes, we will simply accept its unsuitability when sensitive information is involved.
One the other end of the identity effectiveness spectrum might be a solution that provides nearly 100% probability of a subject's identity but is frustrating and close to unusable. For example, a combination of a personal certificate, token, password, and a voice print to access a financial application is a waste of resources and a path to security team unemployment. Identity verification process cost and complexity should mirror the risk associated with unauthorized access and still make sense at the completion of a cost-benefit analysis.
Effective and reasonable identity solution characteristics
Identity verification, like any other control, is stronger when supported by other controls. For example, risk of account ID and password access is mitigated by strong enforcement of separation of duties, least privilege, and need-to-know. Depending on the data involved, this might be enough. For more restricted data classifications, we can use a little probability theory to demonstrate the effectiveness of layered controls. First, however, let us take a look at one of the most common multi-layer solutions: multi-factor authentication.
Multi-factor authentication (MFA)
MFA uses two of three dimensions, or factors:
- Something the subject knows
- Something the subject has
- Something the subject is
Examples of what a subject "knows" include passwords and PINs. Something a subject "has" might be a smart card or a certificate issued by a trusted third party. Finally, biometrics (fingerprints, facial features, vein patterns, etc.) provides information about something the subject "is." Using two of these dimensions significantly increases the probability of correct identity verification.
Probability of identity verification
To demonstrate how a probability calculation might work, lets use an example of three approaches to restricting access to a patient care database, as shown in Figure 11-1. Bella uses only password authentication, Olivia uses fingerprint recognition biometrics only, and Alex uses both a password and fingerprint recognition.
Because of the general environment and business culture restrictions at Bella's workplace, security administrators do not require use of strong passwords. Consequently, we determine the probability that an unauthorized individual can access patient information as 30 percent (P = .30). You might rate this differently. However, the process for determining the relative effect of MFA is the same.
In Olivia's workplace, the security director convinced management that biometrics by itself was strong enough to replace passwords and provide strong-enough identity verification. As we will see in Chapter 12, biometrics is not an identity panacea; it has its own set of challenges. In this case, management requires a low false rejection rate to reduce employee frustration. This results in a probability of 20 percent (P = .20) that someone could masquerade as Olivia and use her login account.
Alex's security director decided to take a middle path. The director believes strong passwords cause more problems than they prevent: a view supported by business management. He also believes that lowering biometrics false rejection rates is necessary to maintain employee acceptance and maintain productivity levels. Instead of using only one less than optimum authentication factor, he decided to layer two: passwords (something Alex has) and biometrics (something Alex is).
The probability of someone masquerading as Alex is very low. We can model this by applying probability theory to our example. As you might recall from our discussion of attack tree analysis, when two conditions must exist in order to achieve a desired state, we multiply the probability of one condition with that of the other. In this case, the desired condition is access to the patient database. The two conditions are knowledge of Alex's password and counterfeiting her fingerprint. Consequently, the probability of an unauthorized person accessing the database as Alex is (.30 x .20) = .06, or six percent.
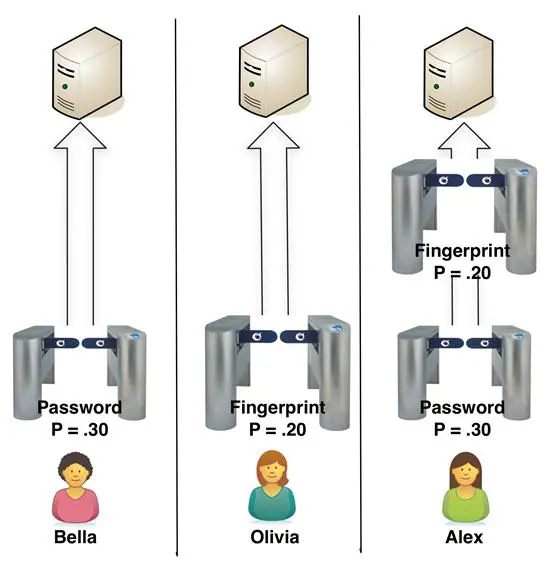
Figure 11-1: Authentication Probabilities
This demonstrates the significant reduction in identity theft risk when using two factors, even if each by itself is relatively weak. In our example, a six percent probability of successful unauthorized access might be acceptable. Acceptance should depend largely on other controls in place, including what data Alex can access and what she can do with it. However, I would not feel comfortable with a 20 or 30 percent probability of access control failure regardless of other existing controls. The actual percentages are not as important as using the model to understand and explain identity verification risk mitigation.
Human versus machine
As we saw in previous chapters, an application can also be a subject. Like Alex in our example above, it also should authenticate its identity when accessing sensitive objects. One method of authentication uses passwords. Unlike human passwords, however, non-human subjects can easily exchange long random character strings that require significant effort to crack. For example, I required 20 character passwords generated by GRC's Perfect Password generator (https://www.grc.com/passwords.htm) for operating system or application services requiring access to databases or other critical systems. I generated the following for our example:
ScIFHqaJHyakm2dSqGJO
I did not require special characters because some implementations do not support anything other than alphanumeric entries. However, our example receives a Strong rating when submitted to the password checker at the Microsoft Safety and Security Center (http://mcaf.ee/firtg). Figure 11-2, the results from the GRC brute force calculator (http://www.grc.com/haystack.htm), gives a more practical idea of what that means. In other words, it would take more time than an attacker can afford to crack our sample password.
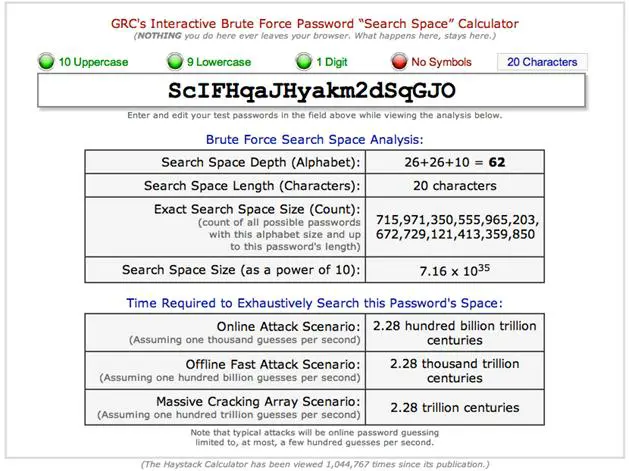
Figure 11- 2: GRC Haystack Results
Strong passwords are useful for authentication between systems in a data center, but they fall short when attempting to verify the identity of an external device. For example, what happens when a remote system attempts a connection to our network? In these situations, certificates might be a better choice.
Certificates, as described in Chapter 7, provide an identity verifiable through a trusted third party. In addition to software and services, human subjects can also use certificates to identify themselves both internally and to external resources.
Authentication, authorization, and accountability (AAA)
Identity management has become a separate consideration for access control. However, the three pillars that support authorized access still define the tools and techniques necessary to manage who gets access to what and what they can do when they get there: authentication, authorization, and accountability. See Figure 11-3.
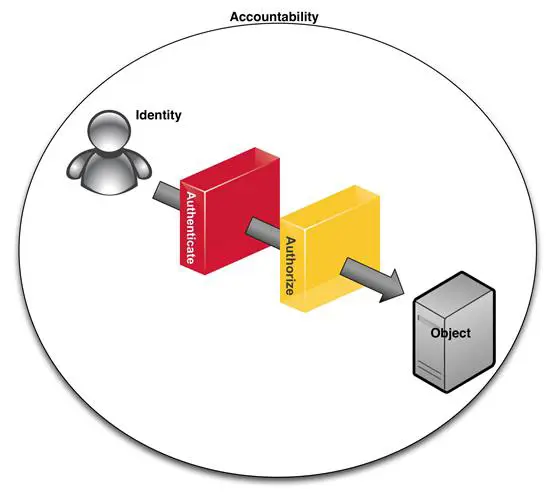
Figure 11- 3: Authentication, Authorization, and Accountability
Authentication
Identity management and authentication are inseparable. Identity management includes assigning and managing a subject's identity. Authentication is the process of verifying a subject's identity at the point of object access.
Authorization
Once a resource or network verifies a subject's identity, the process of determining what objects that subject can access begins. Authorization identifies what systems, network resources, etc. a subject can access. Related processes also enforce least privilege, need-to-know, and separation of duties. Authorization is further divided into coarse and fine dimensions.
Coarse authorization
Coarse authorization determines at a high-level whether a subject is authorized to use or access an object. It does not determine what the subject can do or see once access is granted.
Fine authorization
Fine authorization further refines subject access. Often embedded in the object itself, this process enforces least privilege, need-to-know, and separation of duties, as defined in Chapter 1.
Accountability
Each step from identity presentation through authentication and authorization is logged. Further, the object or some external resource logs all activity between the subject and object. The logs are stored for audits, sent to a log management solution, etc. They provide insight into how well the access control process is working: whether or not subjects abuse their access.
Approaches to access control
The method used to implement AAA varies, depending on data classification, criticality of systems, available budget, and the difficulty associated with managing subject/object relationships. Four common approaches exist to help with access challenges: discretionary, role-based, mandatory, and rules-based.
Discretionary access control (DAC)
If you have given someone permission to access a file you created, you were likely practicing discretionary access control. DAC is the practice of allowing object owners, or anyone else authorized to do so. In its purest form, DAC access is only restricted by the owner's willingness to practice safe sharing. Microsoft Windows works this way out of the box, as does Active Directory. The only constraint on these actions is administrative: policy supported by procedures.
DAC is often a good choice for very small businesses without an IT staff. It allows a handful of users to share information throughout their day, allowing for smooth operation of the business. This approach when applied to 10 or 20 employees lacks the complexity and oversight challenges associated with using DAC in organizations with hundreds or thousands of users.
DAC lacks account onboarding and termination controls necessary to enforce least privilege, need-to-know, and separation of duties for a large number of employees. Further, job changes can result in "permissions creep:" the retention of rights and permissions associated with a previous position that are inappropriate for the new position.
Role-based access control (RBAC)
RBAC largely eliminates discretion when providing access to objects. Instead, administrators or automated systems place subjects into roles. Subjects receive only the rights and permissions assigned to those roles. When an employee changes jobs, all previous access is removed, and the rights and permissions of the new role are assigned. This becomes clearer as we step through Figure 11-4. Before walking through our example, however, we need to understand the various components.
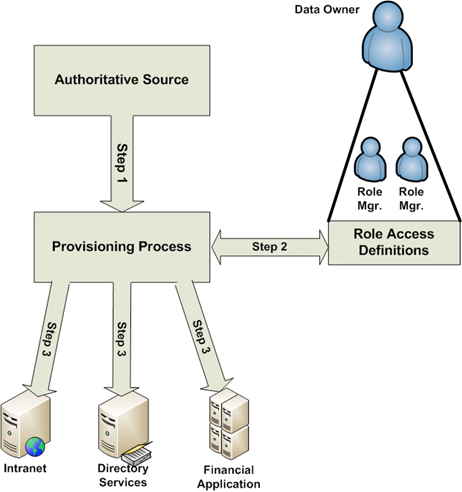
Figure 11- 4: RBAC Model (Olzak, 2011, p. 9)
- Authoritative source. An authoritative source provides information concerning the status of each employee. In most cases, it is the human resources system, which provide business role, new hire, termination, job change, and other information relevant to RBAC management.
- Data owner. A data owner is the person within an organization responsible for risk management for a specific set of data. For example, the vice-president of the finance department would likely be the owner for all data in the financial systems. The vice-president of sales might own responsibility for customer data.
- Role manager. A role manager reports to the data owner and obtains approval for new roles or role changes affecting access to the owner's data. It is the role manager's responsibility to work with security and other IT teams to determine what rights and permissions for the data owner's information a specific role needs. This is often depicted in a matrix listing each user, the business process tasks they perform, and the affected systems. If a role performs tasks in business processes using multiple data types, role definition approval might require sign off by multiple data owners.
- Role access definitions. Each role receives rights and permissions as defined by the role managers and approved by the data owners.
- Provisioning process. Using information from the authoritative source, the provisioning process places or removes subjects from roles. It is either performed manually by administrators (as in many Active Directory implementations) or automated with solutions like those provided by Courion (http://www.courion.com/).
Initial role definition and process setup are not easy and can take weeks or months. However, the results are easy to manage and prevent audit and regulatory issues associated with "winging it." Now we step through a new hire example using our model in Figure 11-4.
Step 1. The day before a new employee reports for work, an HR clerk enters her information into the HR application. Part of this process is assigning the new employee a job code representing her role in the business.
Step 2. That night, a service application extracts changes to employee status from the HR system. The extract is sent to an automated provisioning system or human administrator. If the process is automated, the new hire is quickly added to a role corresponding to her job code. Otherwise, it might take a few minutes after reporting to work for the administrator to drop the new hire's account into the proper role.
Step 3. If automated, the onboarding process uses the appropriate role definition to create accounts in each relevant application and network access solution. A manual process might include adding the new hire's account to one or more Active Directory security groups and creating accounts in applications using application-resident role profiles.
When the employee eventually leaves the company, the process is similar. The HR extract shows her as terminated, and based on her role all access is removed. For a job change, the common approach is to remove all access from the previous role (as if the employee was terminated) and reassign her to a new role. This removes all previous access and helps prevent permissions creep.
Mandatory access control (MAC)
RBAC is a good solution for private industry. It provides everything needed to enforce need-to-know, least privilege, and separation of duties. However, it does not provide constraints necessary to prevent role errors associated with highly classified military or government information. MAC fills the gaps.
Assume Adam assumes a new role at Fort Campbell. In this role, he is responsible for assessing intelligence classified as Secret. The RBAC solution used places him in the right role. However, a change in how data is stored occurred after the role was defined by the role manager and approved by the data owner (Adam's commanding officer). This change inadvertently gives Adam access to a storage device containing Top Secret intelligence. If MAC was implemented in addition to RBAC constraints, Adam's access to Top Secret data would be blocked.
When implementing MAC, administrators tag data elements with appropriate data classifications. Further, user roles or accounts have their own classifications based on clearance levels. For example, Adam's role is classified as Secret. If a role classified as Secret attempts to access a Top Secret data element, it is blocked.
I often describe MAC as RBAC on steroids. While it enforces need-to-know, for example, it prevents access to information above a user's security classification. This is important when protecting national defense secrets. However, the cost of implementing and managing it usually cause MAC to fail a business' cost/benefit analysis test.
Rules-based access control (RAC)
RAC differs from other access control methods because it is largely context-based. RBAC, for example, enforces static constraints based on a user's role. RAC, however, also takes into account the data affected, the identity attempting to perform a task, and other triggers governed by business rules.
A manager, for example, has the ability to approve her employees' hours worked. However, when she attempts to approve her own hours, a rule built into the application compares the employee record and the user, sees they are the same, and temporarily removes approval privilege. Note that this is dynamic and occurs at the time a transaction is attempted. This also sometimes called dynamic RBAC.
RAC is typically implemented in the application code. Developers apply business rules by including rule enforcement modules. Like MAC, RAC prevents role definition anomalies from producing unwanted results. Unlike MAC, however, RAC requires little management; cost is limited to additional development time or purchasing an off-the-shelf solution that already provides transaction context checking.
The future
So far, we have examined traditional approaches to access control. However, with the coming of new technologies the lines between the various approaches are disappearing. A good example of this is dynamic access control introduced in Microsoft Windows Server 2012.
Also known as Microsoft DAC (not to be confused with discretionary access control… Microsoft just couldn't resist making acronyms even more confusing), this integral part of Active Directory 8 extends discretionary and role-based access controls by adding data tagging. Similar to MAC, Microsoft DAC further refines access based on a user's role, enforcing business policy according to context. The following description of DAC functionality is from Microsoft TechNet (2012):
- Identify data by using automatic and manual classification of files. For example, you could tag data in file servers across the organization.
- Control access to files by applying safety-net policies that use central access policies. For example, you could define who can access health information within the organization.
- Audit access to files by using central audit policies for compliance reporting and forensic analysis. For example, you could identify who accessed highly sensitive information.
- Apply Rights Management Services (RMS) protection by using automatic RMS encryption for sensitive Microsoft Office documents. For example, you could configure RMS to encrypt all documents that contain Health Insurance Portability and Accountability Act (HIPAA) information.
When used in conjunction with other Microsoft or compatible third-party solutions, data is protected based on where it is accessed, who is accessing it, and its overall classification with a combination of discretionary, role-based, mandatory, and rules-based access management.
Conclusion
Various methods exist for ensuring only the right subjects access an object while enforcing least privilege, need-to-know, and separation of duties. DAC provides flexibility but little centralized control. RBAC provides centralized control and restricts access to that assigned to approved business roles. MAC adds an additional dimension by preventing users from accessing data at higher classifications than approved for their roles or individual classification. Finally, rules-based access control can dynamically assign or withdraw rights and permissions based on subject/object/process contexts.
What should you learn next?
Regardless of the approach used, the objectives remain the same: verification of identity, effective authorization, and comprehensive accountability for all actions taken against sensitive information and critical systems. Reaching these goals while allowing for anytime/anywhere access is becoming easier as new approaches to identity management and access control combine the advantages of each traditional method.
Sources
- Olzak, T. (2011). Lecture Notes, CMGT430 - Enterprise Security. University of Phoenix .
- Dynamic Access Control: Scenario Overview


- 12 pre-built training plans
- Employer-requested skills
- Personalized, hands-on training
In this series
- Chapter 11 – Identity management and access controls
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
