How to prevent web scraping

Web scraping is a widely used technique that transforms unstructured data on the web (HTML) into structured data which can be stored in a database or a spreadsheet and used or analyzed for various purposes (Wikipedia, 'Web Scraping'). One usage of web scraping would be to get the contents of a website in your own database in order to host it on your own website. Typically, software is used to scrape the websites, such as the Web Scraper Chrome extension or libraries in different programming languages that facilitate the task such as Scrapy, a scraping library for Python.

FREE role-guided training plans
Why should I worry about scraping?
There are many things that can go wrong when somebody is attempting to scrape your website. To start with, the person scraping your website may not be experienced and may launch a bot which performs many requests without pausing between requests. This could lead to a DoS (Denial of Service) situation.
All your web content could be scraped so that involves the possibility of substantial intellectual property/data theft. Your company could lose profit from aggregators and price comparison websites and it can be a subject of information leakage (like AT&T's information leakage discussed below).
What is the legal situation when it comes to web scraping?
It is assumed that web scrapers can steal your data and use it to make profit, which would reduce your own profits. This is particularly evident in the case of third-party aggregators and price comparison websites. To exemplify, Ryanair filled a lawsuit against a handful of companies which were aggregating plane tickets and allowed the user to book through them in exchange for a commission. This resulted in the CJEU (Court of Justice of the European Union) concluding that websites can legally prohibit third parties from scraping their websites, even when the data is unprotected, in the case when they explicitly prohibit scraping in their terms and conditions (CJEU and web scraping).
In the USA, things are heading the same way. Andrew Auernheimer was convicted for hacking when all he did was scrape the AT&T website and gathered publicly available information. His scraping endeavor was viewed as a brute force attack (weev and AT&T hacking). Before that, many suits in the USA succeeded against websites that employed web scraping such as Facebook's lawsuit against Power.com which aggregated social network accounts and provided a single interface to manage them. In that particular case, Power.com was found liable and was ordered to pay $3 million in damages to Facebook.
Preventing web scraping
Let us say we have a simple blog-like website that shows different articles to users.
Figure 1: The homepage of the website
Figure 2: Viewing all articles contained in the website
Figure 3: Viewing a particular article in the website
Some of the techniques mentioned below will be exemplified through this sample website.
Terms of use
One way to prevent your website from being scraped is to declare explicitly that you disallow such actions in your Terms of Use and Conditions. While this will not deter everybody, the case law in the European Union will probably be on your side if such a condition is in place. Here is an example of such a condition:
"You may only use or reproduce the content on the Website for your own personal and non-commercial use.
The framing, scraping, data-mining, extraction or collection of the content of the Website in any form and by any means whatsoever is strictly prohibited
Furthermore, you may not mirror any material contained on the Website."
This would indicate that one cannot extract, mirror or use the content of the website for any other purpose than personal.
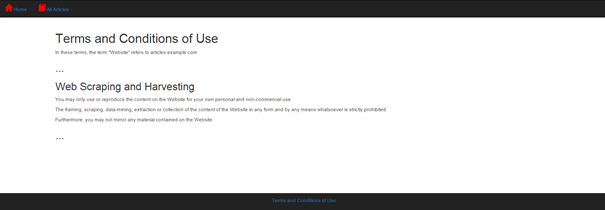
Figure 4: The terms of use implemented in the sample website
However, as with the current legal uncertainty that would not guarantee you 100% deterrence. Thus, let us examine other more efficient methods of combatting Web Scraping.
Honeypots
Honeypots enable you to capture the IP addresses of people scraping your website or automatically disallow them access to your website. To implement a honeypot in our sample website we create a class with a static function which generates honeypot articles. Those are hidden dummy articles which instead of linking to an article would link to a page which will capture the scraper's IP address. To prevent capturing legitimate bots we would disallow access to the honeypot in our robots.txt file. Thus, legitimate crawlers such as the ones Google employs would not open the honeypot but most scraping software would disregard such prohibitions and just follow the instructions given to it – in our case – scrape the content of all articles from the website.
Here is the function that would construct a honeypot article.
<?php
class Honeypot {
public static function craft($type) {
if ($type === 'article') : ?>
<div style="display: none;" class="article-entry col-lg-4">
<h1><a href="/articles/trap/?name=Hello-World"></a></h1>
<p>Hi, bad folks</p>
</div>
<?php
endif;
}
}
You can see the honeypot article links to articles/trap… instead of merely linking to the articles path.
Thereafter, we create a robots.txt file and input the following:
User-agent: *
Disallow: /articles/trap
This would prevent legitimate bots from opening the honeypot and having their IP addresses captured.
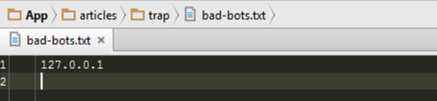
In our trap folder, we create a simple script which just stores each IP address that accessed the page on a separate line:
file_put_contents('bad-bots.txt', GetIp() . "rn", FILE_APPEND);
That's all there is to it. Let us see how it works by scraping the website with the Web Scraper Chrome extension.

Figure 5: We have created a sitemap in Web Scraper that starts scraping from the articles page of our website

Figure 6: We open each link corresponding to the selector .article-entry a (to view the contents of each article)

Figure 7: Thereafter, we instruct Web Scraper to extract the content of each opened article
Now, we instruct the Web Scraper to start scraping…
Figure 8: The Web Scraper Chrome extension is scraping the sample website
When it finishes, we can see one of the results contains null values. This is so because the extension fell for the honeypot and tried to open the article but there was nothing there.

Figure 9: Successful honeypot
Furthermore, if we check the trap folder we would see the bad-bots.txt file has been created and is filled with an IP address.

Get your guide to the top-paying certifications
With more than 448,000 U.S. cybersecurity job openings annually, get answers to all your cybersecurity salary questions with our free ebook!
Cookies and JavaScript
Since most scrapers out there are not real browsers, many of them have trouble executing JavaScript or/and storing cookies.
This means that a way of protection against some of the bots could be to set a cookie and/or execute a JavaScript and do not render the contents unless the cookie is successfully stored or/and the script is executed.
However, this approach poses some usability issues as users could disable cookies and JavaScript themselves which will hinder them from accessing your page.
A small study in 2009 revealed that from 13,500 people 3.7% disable all cookies while around 1% disables JavaScript (A study of Internet users' cookie and JavaScript settings). Those numbers should be even lower today.
Let us now examine a scraper which is not browser-based. We are going to use the Goutte Web Scraper library for PHP to do the exact same thing – capture and store the contents of all articles – this time in JSON format.
The code that enables us to scrape all the articles looks like that:
<?php
require_once("vendor/autoload.php");
use GoutteClient;
$articles = array();
$client = new Client();
$crawler = $client->request('GET', 'http://dimoff.dev/articles');
//select each link to an article
$crawler->filter('.article-entry a')->each(function ($node) {
global $crawler, $client;
$text = $node->text();
if ($text) {
//click on each article's link
$link = $crawler->selectLink($text)->link();
$newPageCrawler = $client->click($link);
$newPageCrawler->filter('.col-lg-10')->each(function ($node){
//store the article's contents in the $articles array
global $articles;
$body = $node->filter("p")->text();
$title = $node->filter("h1")->text();
$articles[$title] = $body;
echo "Scraped an article!<br>";
});
}
});
file_put_contents('results.json', json_encode($articles), FILE_APPEND);
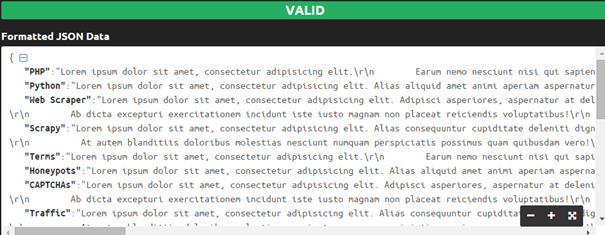
Figure 10: JSON containing the scraped articles with Goutte
Now, we are going to effectively block this tool by giving the correct response filled with articles only if the user has both JavaScript and cookies enabled. Though you should remember that this may be a hindrance in terms of usability.
We create a simple class with a static function in PHP which when first called will try to set a cookie through JavaScript and reload the page (the cookie will be available after a refresh if JS and cookies are enabled). Only if such a cookie already exist it would return true. If the function returns true – then we know that the user has both JavaScript and cookies enabled.
<?php
class isBrowser {
public static function test() {
if (!isset($_COOKIE['jsEnabled'])){
echo "<script>
if (navigator.cookieEnabled) {
document.cookie = 'jsEnabled=1;';
window.location.reload();
}
</script>";
return false;
}
return true;
}
}
Then, we can use the function anywhere we like to check if the user has both JavaScript and cookies enabled. In our case, we added the test to each page by placing it in the header that all pages of the website share:
<head>
<meta charset="UTF-8">
<!—Some other tags here -->
<?php
require_once("/classes/isBrowser.php");
if (!isBrowser::test()) {
echo "You have JavaScript or/and cookies disabled. Come back when you enable them";
exit;
}
?>
</head>
It can be seen that we merely check if the return value of the function is false and if it is we display a warning message and stop processing any further code.
If we run the Goutte scraper that we set up before it would not collect any data as it can be seen in the picture below.
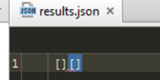
Figure 11: Two attempts to run the Goutte scraper and both returned an empty array because Goutte cannot handle cookies and JavaScript.
On the other hand, most users would have a rather normal experience as it can be evidenced by the picture below.
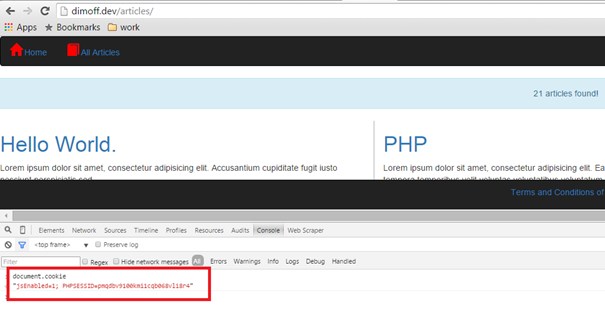
Figure 12: Users who have JavaScript and cookies enabled would be able to browse the website as usual. Once per browsing session they will be redirected once to establish if they are using a standard browser.
Alternatively, you could block the page from rendering only when the user has both cookies and JavaScript disabled. In our example, if only cookies or only JavaScript are disabled – the user would still be unable to access the website. This can be less restrictive for our users, if we decide to implement such a preventive measure.
Note that you would also have to think about ways to allow legitimate crawlers (such as the ones from Google, Yahoo or Bing) if the content on the pages protected by this technique is meant to be crawled by them.
CAPTCHAs
We can add a CAPTCHA that users would have to solve before accessing any content. This hinders the user experience quite a lot if the CAPTCHA is shown with each request. Therefore, it might be better to show the CAPTCHA only when you detect a large number of requests over a small period of time. It is also not bulletproof, as there exist bots, which are capable of solving CAPTCHAs, but it does reduce scraping attempts, especially if mixed with other techniques as well.
Impose a limit on requests
Scrapers access many more pages than ordinary users; they usually open webpages after a specified interval that does not change. Those are all ways that can help us determine if a user is actually a scraper. Imposing a rate limit could either slow down scrapers, especially if there is a substantial amount of content in the website or completely stop the scraping process depending on what we want to do after the rate limit has been reached. For example, we can set a rate limit of 200 requests per hour, keep track of the number of requests made by a given user to the website, return a 429 (Too many requests) HTTP response if a user reaches the limit and reset the number of user requests made every hour.
Obfuscating your data
Depending on your needs, you may want to show sensitive web content inside an image, CSS background property, a flash file or in a similar disguise to prevent scrapers from getting to your data and making sense of it.
Blocking known scrapers
If you know that a rival company, an aggregator or a price comparison website is scraping your content you can probably find out the IP address range their scrapers use. This allows you to block all requests coming from within those ranges and effectively stop their scraping activity. This does not mean that they cannot resort to proxies, Tor or use another means to disguise their identity.
Legal action
If nothing works, you can always resort to a lawsuit against the company that scrapes your website. We discussed briefly the legal situation as of this moment and it is possible to win a case against the unauthorized scrapers.
Get your guide to the top-paying certifications
With more than 448,000 U.S. cybersecurity job openings annually, get answers to all your cybersecurity salary questions with our free ebook!
Conclusion
There are numerous techniques to use that can combat scrapers. No single technique offers full protection but if we combine a few, we can make a pretty successful deterrent for scrapers.
Sources
- Stack Overflow, "What is the best way of scraping data from a website"
- Out-Law.com, 'Website operators can prohibit 'screen scraping' of unprotected data via terms and conditions, says EU court in Ryanair case'
- EFF, 'Facebook v. Power Ventures'
- Stack Overflow, 'How do I prevent site scraping?'
- Smorgasbork, 'A study of Internet users' cookie and JavaScript settings'.
- IMPERVA, 'Detecting and Blocking Site Scraping Attacks'.


- 12 pre-built training plans
- Employer-requested skills
- Personalized, hands-on training
In this series
- How to prevent web scraping
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
