An Introduction to Data Masking

Background:
Dealing with Production Data is a challenge, but most organizations around the world have safeguards in place which secure the production environment properly.However,when it comes to non-production environments like Dev (Development) environment or Test Environment etc., they still do not have proper security in place. Protecting sensitive data is not an only an organization's moral responsibility, but in certain cases it is also demanded by governing standards. This data can belong to customer or even organization's employees.

11 courses, 8+ hours of training
Either way, proper protections should be in place to ensure that data residing with the organization is secure.
Objective & Scope:
This article will focus on giving readers an overview of data masking. Implementation strategies that focuses on the "how to" factor of data masking solutions are out of scope for this article. Having said that, we'll still cover an example which shows how the entire process works to simplify the concept and explain the same to the users.Readers should note that this is not the only way in which data masking can be performed.
The aim of this article is to introduce users to the concept of data masking and what it can achieve for an organization. We will also list some of the commercial products which can be used for masking sensitive organization data.
What is Sensitive Data?
The definition of Sensitive data is pretty broad and changes from country to country, organization to organization, and even individual to individual. In some country like United States – data like the Social Security Number is considered to be extremely sensitive. Similarly health records also are considered sensitive information.
Globally, every county accepts that Credit/Debit Card Data is sensitive data – explicitly the Card Number and Pin/CVV/CVV2 details.
While we have discussed SSN and Card Data, we covered regionally. Every organization also has certain data classified as sensitive. Example: An Employee's salary details can be considered to be sensitive data. Similarly,intellectual property or research data is also considered to be sensitive in nature. This changes from organization to organization.
Why Secure Data?
There have been cases where critical customer data, when lost, causes an organization to face lawsuits and spend millions of dollars to settle them. This can be a huge cost to any organization in an unfortunate event where critical customer data is lost.
Certain compliance standards like PCI DSS have specific requirements that deal with Data Security. I will not cover each and every compliance standard, however I will explain PCI DSS standard as one example.
One of the PCI DSS Requirements 6.3.4 says "Production data (live PANs) are not used for testing or development"
The requirement stated above is clear enough – an organization can't use live PAN (Permanent Account Numbers). However the trickier part is implementation. Without this data – how to develop and test the application? As a matter of fact, we just need a Permanent Account Number, it need not be a valid one!
Understanding this clearly can help us mask our data by mapping existing live PAN's to dummy PAN's. Testers only need production like data which can help them simulate testing – not the live data. PCI DSS requirement emphasizes on PAN's because this is one of the most sensitive card holder data. The requirement further adds that production data should not be used in development or Testing environment. This is where data masking can be helpful.
What is Data Masking?
Data masking is nothing but obscuring specific records within the database. Masking of data ensures that sensitive data is replaced with realistic but not real data in testing environment thus achieving both the aims – protecting sensitive data and ensuring that test data is valid and testable.
There can be many ways in which data masking can be implemented. It could be as a substitution of existing records with expected test data or shuffling of certain characters or numbers, thus generating a new record.Alternately, it could be as complex as using proprietary algorithms to scramble or obfuscate a part of the record with a random data generated using the algorithm which has all properties that original data had.
Data masking is not just about Test Data. In fact this concept can be applied to every situation where an organization does not want to reveal real data. Example: Salary information of every employee. Whether any compliance standard explicitly considers this as sensitive data or not, salary-related information still remains sensitive information from an organization's standpoint, and thus protecting the same makes sense for it. Data masking techniques can be applied here as well. There can be many such scenarios. Following section explains this example in detail to understand how
Sample Scenario:
Let's try and expand on the problem statement discussed previously. How can we ensure that valid test data is present, but at the same time, we are not leaking any employee's salary either? We can't change employee id's or numbers because employee id or numbers can be primary keys in the database messing around with these records and applying encryption, or changing the primary key will render data records useless.
We can solve this problem by scrambling the salary details of employees. However, there are a couple of challenges before we scramble the details. If the expectation is to recover the scrambled data back, it may not be straight forward. Assuming that live data is independent and we are not concerned with what happen to test data as long as length, data type and other business constraints are met, we can use Data Field Substitution to change the test data.
We can create a copy of employee's salary field and randomize the records. Once we have a list of randomized salary fields ready, we can use it to replace the existing salary fields by replacing them with the new list. Alternately, we can also create a list of salaries on our own and then replace them. The end goal is to ensure that each employee's salary is scrambled with realistic data – but not real data.
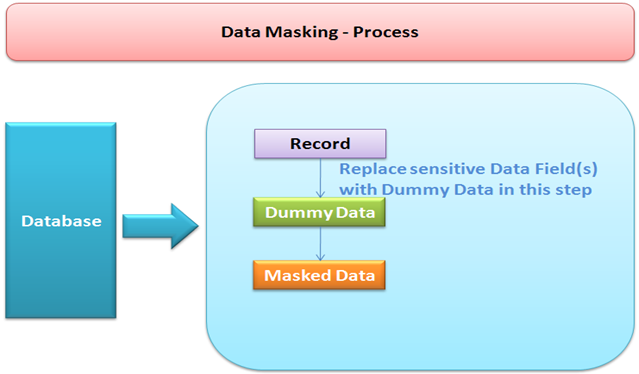
Things to consider when Masking Data:
Following are some of the things that should be kept in mind when designing/choosing a solution to mask sensitive data fields.
-
Non-Reversible
It should not be possible to retrieve original sensitive data by reversing the masking process. If one is able to reverse the process to retrieve the sensitive data back, it defeats the entire purpose of masking the data. -
Masked data should resemble production data:
This is one more key point that needs to be considered. Data should resemble live data – otherwise testing could be a challenge. Hence when a solution is designed or purchased for masking of sensitive data, this point should be taken into consideration. -
Maintain Referential Integrity:
If the data field being manipulated is a primary key, an appropriately foreign key should also be referencing the masked data field, else referential integrity will not be maintained and there will be a foreign key which in some table which does not have any corresponding primary key. This means that if employee ID is a primary key and if this field is scrambled, then all instances of that field must be scrambled identically. -
Repeatable:
Masking should be a repeatable process. Production data changes frequently – at times hourly. If the data masking solution provides support only for single time masking, it can be a problem because newly added records will not be masked. -
Database Integrity:
Apart from maintaining Referential Integrity, solution should also be able to take care of triggers, keys, indices etc. It should be able to discover relationships between all database objects automatically and should be able to maintain the state accordingly. -
Pre-packaged Masked Data:
If the solution is being purchased, then organization should also look for support for pre-packaged masked data for general requirements like credit card numbers, Social Security Numbers etc. The solution in question should be have sample data ready – especially for data fields which are mandated by compliance standards like PCI DSS, HIPAA, SOXetc.
Please note that this is not an exhaustive list of features. These are just some of the features which author believes should be considered. Most commercial solutions these days have many more features and a thorough evaluation should be performed before choosing a solution.
Commercial solutions:
There are commercial solutions which cater to business requirements for masking sensitive data, such as the following:
- Camouflage
- IBM Infosphere Optim Data masking Solution
- Infosys Data Masking Solution
- Oracle Data Masking Solution
- Informatica Dynamic Data Masking
- HP Test Data Management
References:
http://en.wikipedia.org/wiki/Data_masking
http://www.oracle.com/us/products/database/data-masking-161222.html
http://www.informatica.com/us/products/data-masking/

11 courses, 8+ hours of training


Learn how to secure systems with 11 courses from Infosec Skills instructor and #1 best-selling author Ted Harrington.
- Hack your system
- Establish your threat model
- Spend wisely
- And more
In this series
- An Introduction to Data Masking
- CompTIA CySA+ Salary: What to expect in 2025
- How to become a cybercrime investigator
- CEH version comparison: V12 to V13 evolution guide
- SecurityX (CASP+) certification: Overview and career path [2025 update]
- Network+ certification: Overview and career path [2025 update]
- ISC2 CSSLP certification overview: What you need to know
- ISC2 CGRC: Overview & career path
- CRISC certification: Overview & career path [updated 2021]
- PMP certification: Overview and career path [updated 2021]
- ISACA CDPSE certification: Overview of the new ISACA privacy certification
- CGEIT certification: Overview and career path [updated 2021]
- What is a cyber range?
- Microsoft azure certification: Overview And career path
- CEH salary guide: What Certified Ethical Hackers really earn
- Average SecurityX (CASP+) salary [2025 update]
- CompTIA Network+ certification — A 2025 salary analysis
- CompTIA CySA+ exam (CSO-003): Your guide
- CCSP salary: How much can you make as a cloud security professional?
- Average Security+ salary (2025): Your guide to a prosperous cybersecurity career
- Average CGRC (Certified in Governance, Risk and Compliance) salary
- CRISC Frequently Asked Questions (FAQ) [updated 2022]
- Average CSSLP Salary in 2021
- ISACA CDPSE exam details and process
- How To Become CGEIT Certified – Certification Requirements [updated 2021]
- How to pick the best cyber range for your cybersecurity training needs and budget
- CEH exam eligibility: Application process & requirements guide
- SecurityX (CASP+) frequently asked questions (FAQ) [2025 update]
- CISSP domains overview: Your complete preparation guide
- CCSP exam and CBK changes in August 2024
- Comprehensive guide to CompTIA Security+ domains (2025)
- Average CRISC Salary [2023 update]
- CGRC certification job titles and career outlook
- ISC2 CSSLP exam details and process
- ISACA CDPSE certification exam: Overview of domains
- An Introduction to the PMP: Exam Details and Process [updated 2021]
- CGEIT certification exam: overview of domains [Updated 2021]
- 10 Success Tips: How to Pass Your Certified Ethical Hacker (CEH) Exam
- Network+: Exam details and process [2025 update]
- SecurityX (CASP+): Exam details and process [2025 update]
- How to become CCSP certified: Certification requirements
- Certified in Risk & Information Systems Control (CRISC) Exam Overview [updated 2022]
- ISC2 CGRC exam details and process
- Best CSSLP study resources and training materials
- ISACA CDPSE domain 1: Privacy governance
- 10 Tips for PMP Certification Exam Success [updated 2021]
- CGEIT certification exam details and process [updated 2021]
- Certified Ethical Hacker (CEH) study guides & resources [updated 2025]
- CompTIA SecurityX resources: Videos, books, tests and more!
- How to get the CompTIA Network+ certification: Requirements and step-by-step instructions [2025 update]
- CySA+ exam objectives: The 4 domains that will be covered
Get certified and advance your career!
- Exam Pass Guarantee
- Live instruction
- CompTIA, ISACA, ISC2, Cisco, Microsoft and more!
CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
