Buffer Overflow Vulnerabilities

Introduction to buffer overflows
Buffer overflows are considered the most dangerous vulnerability according to the CWE Top 25 list in 2019. They received a score of 75.56, almost 30 full points higher than the second-ranking vulnerability (cross-site scripting). The reason for this high score is that a buffer overflow vulnerability, if exploited, grants an attacker a large degree of control over a program’s execution and enables execution of attacker-provided malicious code.
Buffer overflow vulnerabilities are created when a developer fails to appropriately manage memory for user-controlled data. If a user can put more data into a pre-allocated memory buffer than the buffer can hold, they can dramatically impact the operation of a program.
Learn Secure Coding
User input and memory management
Every piece of data on a computer that is used by a program has to be stored somewhere. When a program is running, this “somewhere” is either the stack or the heap. While both of these can be the victim of buffer overflow attacks, stack-based ones are the best place to begin.
The stack is a region of memory where a program can store values for later use. It grows when new values are added to the top of it, like a stack of papers (hence the name).
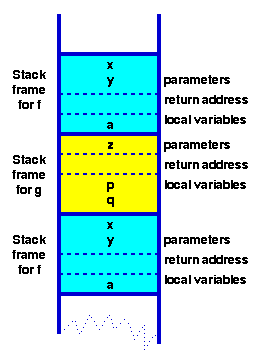
The image above shows a sample program stack. As shown, a function’s stack includes function arguments/parameters, local variables and the function’s return address. If an attacker can rewrite the function return address, they can control the execution flow of the program and potentially convince it to run attacker-controlled malicious code.
When placing data on the stack, a developer can allocate a variable with a set size to hold that data and then fill it with data. As long as the data fits in the allocated variable buffer, then everything works out.
Buffer overflow vulnerabilities
Buffer overflow vulnerabilities are created when the developer does not account for and control the potential case where the allocated buffer is not large enough to hold the data that is to be placed in it. This typically is only an issue when dealing with user-controlled data.
Most buffer overflow vulnerabilities boil down to the use of unbounded read or copy operators like strcpy and strcat in C++. These operators are designed to read data into a buffer until they reach a null terminator. They don’t know or care how long an allocated buffer is and will happily write beyond its boundaries if they don’t hit a null terminator. A malicious user can use this to overwrite the function return address — or other important variable values — and impact the operation of the program.
The simplest way to mitigate buffer overflow vulnerabilities is to avoid the use of unbounded write operators. Functions like strncpy and strncat take an argument specifying the length of the input that they should copy over and will stop when they reach a null terminator or the maximum length, whichever is sooner.
However, these are not a perfect solution to the problem. This is because they assume that the developer has correctly specified the length of the data that they wish to have written to the buffer. A wrong value in the length argument for strncpy will still allow exploitation of a buffer overflow vulnerability. Even if the developer has done their math correctly, an integer overflow vulnerability can enable an attacker to write a value greater than the intended length.
Protecting against buffer overflow vulnerabilities
Buffer overflow vulnerabilities can be very dangerous, as demonstrated by their high rank in the CWE list. Despite being one of the best-known types of vulnerabilities, they still commonly appear in applications: they can be very difficult to detect, and even “safe” code can be exploited if an integer overflow vulnerability exists as well.
The prevalence and impact of buffer overflow vulnerabilities have resulted in the creation of many different mechanisms for protecting against them. Modern operating systems use tools like stack canaries, data execution prevention (DEP) and address space layout randomization (ASLR) to prevent the abuse of buffer overflow vulnerabilities to run attacker-controlled code (also called return-oriented programming).
Programming languages also have taken steps to protect against buffer overflow vulnerabilities. C++ has introduced functions like strncpy and strncat to replace their more vulnerable versions, although even these more “secure” versions can be vulnerable. Other languages, like Java, include automatic bounds-checking of buffers to make buffer overflow attacks impossible.
These steps have made it more difficult to exploit buffer overflow vulnerabilities, but not impossible. These vulnerabilities continue to exist and threaten the security of a wide variety of applications, even including ones developed by large companies like Facebook’s Whatsapp, which contained two major buffer overflow vulnerabilities that were disclosed and patched in 2019.
Learn Secure Coding
Sources
- 2019 CWE Top 25 Most Dangerous Software Errors, CWE
- Data Structures and Algorithms, cs.auckland.ac.nz
- Projects, OWASP

CompTIA CySA+
Discover the latest salary trends for CompTIA CySA+ certified professionals in 2024. Learn what factors influence your earning potential in the cybersecurity field.

Cybercrime investigator
Cybercrime has hit record levels, with an expected $7 trillion USD to be made from cybercriminal activity by 2021. Investigating these sorts of crimes can be

EC-Council CEH
CEH v13 is the world's first AI-powered ethical hacking certification. Discover what's new, how it compares to v12/v11 and why it's a career game-changer.

CompTIA SecurityX
Explore the expert-level CompTIA SecurityX certification, what to expect on the exam, the career benefits and more.
